 Прозрачность — супермощный инструмент в руках грамотного менеджера. Те, кто только начал организационные изменения для уменьшения времени выпуска (lead time), могут пока сомневаться. Бывалые, и их мнение я полностью разделяю, считают прозрачность более эффективным способом воздействия на умы и культуру, даже чем административный ресурс. Постараюсь объяснить, что я имею ввиду.
Прозрачность — супермощный инструмент в руках грамотного менеджера. Те, кто только начал организационные изменения для уменьшения времени выпуска (lead time), могут пока сомневаться. Бывалые, и их мнение я полностью разделяю, считают прозрачность более эффективным способом воздействия на умы и культуру, даже чем административный ресурс. Постараюсь объяснить, что я имею ввиду.
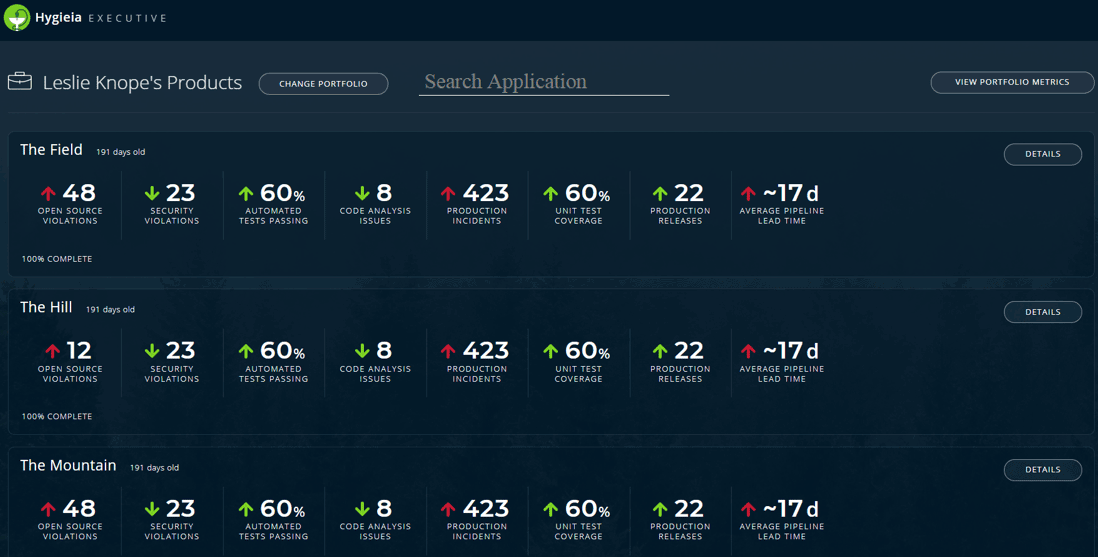
Прозрачность — это объективное открытое знание, во-первых, значений ключевых метрик, а во-вторых — уровня соответствия принятым в компании стандартам и практикам. Для каждого продукта и для каждой продуктовой команды.
Какие самые основные метрики DevOps? Их очень немного, и для начала измерений можно обойтись ограниченным набором:
- время нахождения идеи в бэклоге (пока не взяли на реализацию)
- время прохождения задачи от «взяли» до «в продуктиве»
- доля выполненных задач, которые принесли ожидаемую пользу
- предсказуемость выполнения взятых на себя задач за определённые отрезки времени
К этому базовому набору, разумеется, можно добавить по вкусу много всего прочего: и про velocity, и про MTTR с MTBF, и про расход ресурса на устранение дефектов и инцидентов — список бесконечен. Но не в длине списка дело, конечно же.
Второй элемент прозрачности, о котором было сказано выше, касается организации работы. Но не «по книжкам» и скрам-гайдам (простите, такое тоже бывает), а по принятым в компании стандартам и практикам. Они должны определять что такое хорошо и что такое плохо для конкретной организации, к примеру:
- способна ли команда работать без выделенного лидера/начальника/координатора/супервайзора/руководителя
- каково покрытие тестами модулей и есть ли вообще практика разработки таких тестов
- какие операции допустимо выполнять вручную, а какие должны быть автоматизированы
- есть ли карта развития продукта и насколько она актуальна
- вынуждены ли участники команды отвлекаться на какие-либо задачи за пределами данного продукта
Снова замечу, список может быть сильно длиннее, а может быть совсем иным — в нём как раз и отражается специфика конкретной организации.
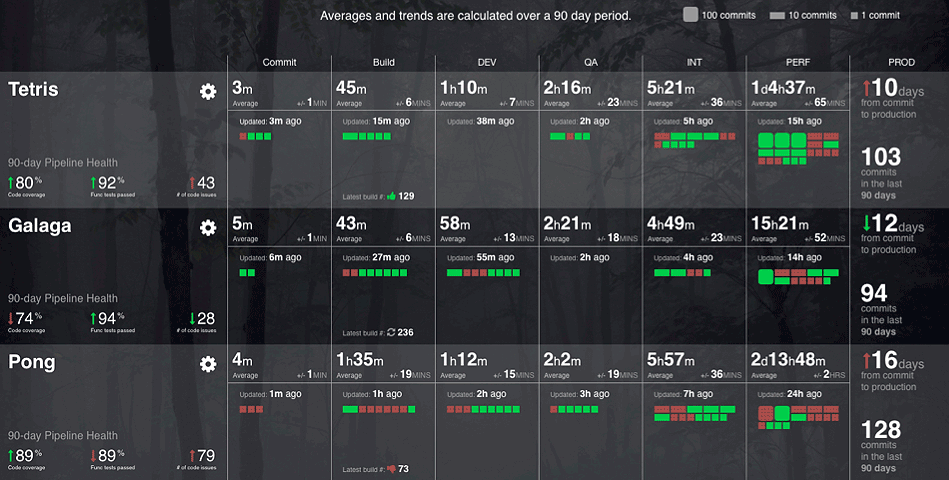
Такой управленческий инструмент позволяет решать две задачи.
Во-первых, в руках менеджера он показывает объективную картину по всем командам, что позволяет не только оценить состояние, но и понять где требуется внимание. Из опыта известно, что применение новых практик никогда не происходит равномерно по всем частям организации — да что там, даже по выделенным пилотным зонам никакой равномерности не наблюдается. Также известно, что те самые новые практики не появляются сами собой, их становлению нужно помогать. Учитывая, что ресурс руководителей, методологов и прочих коучей ограничен, очень важно в любой момент времени понимать куда его лучше всего направить.
Во-вторых, в руках команды такой инструмент позволяет сравнить себя сегодня с собой же позавчера, а также с другими командами. Сами участники команды могут наблюдать свою собственную динамику, а также динамику других. Очень быстро и довольно наглядно становятся видны традиционные группы, о которых нам так замечательно рассказывали Джон Коттер и Вильям Бриджес — лидеры, середнячки и отстающие. Такие группы становятся видны не отдельному «управляющему комитету», а всем. И именно это само по себе положительно влияет на принятие нового. Для сравнения можно попробовать представить будет ли более результативной команда сверху: «Срочно всем уменьшить time to market!». Думаю, что не очень.
Итак, для успеха затеи по организации высокоскоростного создания ценности в ИТ через разработку программного обеспечения совершенно необходимо на самых ранних стадиях преобразований создать вот такую прозрачность. Однако в действительности не всё так просто.
Первая часть, ключевые метрики, относительно несложна. У всех же нынче есть Jira — нужно только настроить в ней грамотный учёт задач с требуемыми отсечками времени, хотя бы даже по статусам. Уже полдела сделано! Остальные метрики подтянем.
Засада поджидает нас во второй части, стандарты и практики. Откуда их взять? Как компания поймёт, что для неё хорошо, а что плохо? Для примера можно провести простой эксперимент. Опросите несколько разработчиков ПО одной и той же компании, работающих над разными продуктами, задачами, применяющих разные технологии. Вопрос задавайте один и тот же: как должно быть организовано тестирование программного кода? Зачастую пространство мнений может начинаться с тезисов вроде «автоматическое тестирование — зло и лишняя трата ресурсов«, переходить к «мы иногда пишем тесты, но в основном всё вручную«, далее к «на каждый найденный в продуктиве дефект мы обязательно напишем тест, чтобы больше не повторялось» и вплоть до «мы сначала пишем тесты, всегда, и только потом разрабатываем функциональность«. Понятно, что тема тестирования широка, но на данном примере хорошо видно, что даже в одной и той же организации мнений о том что такое современная разработка ПО может быть столько же, сколько сотрудников. И это ведь не просто мнения, это практика, разная в разных частях компании.
Таким образом, чтобы получить супермощный инструмент, сначала придётся хорошенько поработать. В каких ещё направлениях работать можно обсудить на нашем учебном курсе «Основы DevOps» (поймите, я не мог его не упомянуть). Как видно из заметки, на этом курсе мы обсуждаем вовсе не софт для построения конвейера, а также не животрепещущий вопрос Docker vs. Kubernetes, а именно управленческие задачи и решения. Совсем скоро, через две недели, я буду проводить этот курс в дистанционном формате, что удобно для тех, кому далеко добираться до Москвы. Если вы дочитали до этого места — приходите на курс, нам есть о чём поговорить!
