Недавно на одной из внутренних тусовок, где обсуждали Канбан для продуктовых команд, мимоходом была озвучена мысль о том, что коэффициент эффективности потока нынче уже не в моде, поскольку не учитывает задачи, зависшие в производственной системе.
Попробую возразить.
Для того, чтобы это сделать, стоит напомнить, что это за метрика, и сделать пару уточняющих охват заметки замечаний.
Коэффициент эффективности потока (FE) показывает какую долю времени, проведённого задачей (work item) в производственной системе (т.е. lead time, LT), задача действительно обрабатывалась (т.е. велась работа над её решением). Если просуммировать это «чистое» время обработки мы получим так называемое время обработки — process time (PT, aka touch time, TT). Таким, образом FE = PT/LT. Подробно про этот коэффициент и, что самое главное, ключевые особенности его использования писал Олег Скрынник в заметке «Метрика эффективности потока, похоже, совершенно бесполезна».
Замечание первое. Каждая метрика отвечает на ограниченный набор вопросов. Странно ожидать что любая конкретная метрика покажет всё, что нам хотелось бы знать об объекте управления. Метрика — это инструмент. Не стоит ожидать от любого инструмента даже самого универсального пользы для решения абсолютно любых задач. Например, молотком можно делать бутерброды, швейцарским ножом измерять расстояние или массу. Но неудобно. И качество так себе. В частности, для отслеживания накопления задач в системе можно их и считать. А чтобы ограничить накопление, использовать WIP-лимиты. Итого, я не пытаюсь доказать, что FE «помогает от всего».
Замечание второе. В этой заметке я не буду рассматривать сложности подсчёта PT. Они существуют. Этот вопрос затрагивается в том числе в упомянутой выше заметке, а варианты решения задачи мы разбираем на наших курсах (например, на курсе «DevOps: современный подход к организации работы ИТ»). Также понятно, что обработка задачи может выполняться неэффективно, т.е. при высоком значении числителя (PT) и соответственно более высоком значении FE, мы на самом деле можем иметь дело с просто медленно выполняемой работой. Сейчас не об этом. Т.е. в данной заметке я хочу поговорить в основном о том, как рассчитывать PT и LT.
Поэтому давайте разберём суть претензии к FE, к которой начинается данная заметка.
Если считать FE по одной задаче, то обычно выбирают наиболее типовою задачу, или задачу из класса задач, с которым важно разобраться. Чтобы иметь более полное представление о производственной системе, можно посчитать среднее значение. Например, так:
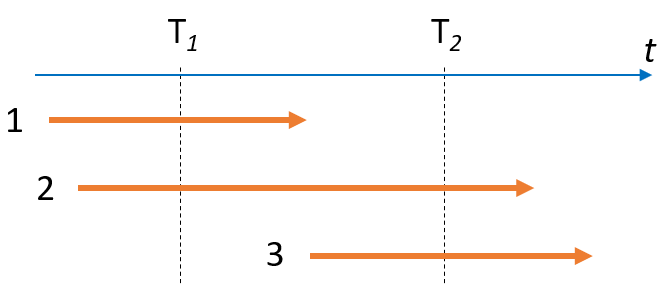
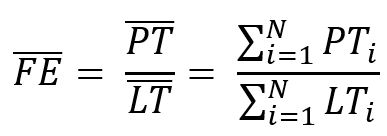 где N — это количество выполненных за отчётный период задач. Т.е. количество work items, обработка которых завершена в производственной системе за отчётный период (например, неделя или месяц). К другим задачам, т.е. к тем, которые попали в нашу производственную систему, но не завершены, понятие LT неприменимо по определению lead time (на рисунке задачи 2 и 3 не попадут в расчёт, а задача 1 попадёт [предполагаем, что конец стрелки соответвует моменту времени, когда задача решена]).
где N — это количество выполненных за отчётный период задач. Т.е. количество work items, обработка которых завершена в производственной системе за отчётный период (например, неделя или месяц). К другим задачам, т.е. к тем, которые попали в нашу производственную систему, но не завершены, понятие LT неприменимо по определению lead time (на рисунке задачи 2 и 3 не попадут в расчёт, а задача 1 попадёт [предполагаем, что конец стрелки соответвует моменту времени, когда задача решена]).
В таком виде FE, кажется достовернее отображает поведение нашей системы. Физический смысл такого коэффициента, как мне кажется, наиболее очевиден в правой формулировке: «Все задачи, решённые в текущем отчётном периоде, провели в нашей производственной системе какое-то время — объём этого времени указан в знаменателе (стоит отметить, что LT конкретной задачи может превышать длительность отчётного периода; к сожалению, иногда кратно). Какую-то часть этого времени каждая задача действительно решалась. Суммарный объём этого времени указан в числителе — PT (важно помнить, что это не трудозатраты)». То есть FE, как и задумывалось, показывает, как работает наша производственная система; что там происходит с задачами — они в нашей системе просто находятся, или всё-таки они в нашей системе решаются.
Претензия же к данному показателю заключалась в том, что он может не отображать неэффективность производственной системы, выражающуюся в том, что система (например, продуктовая команда) набирает огромное количество задач, при этом быстро решая одиночные задачи. Поскольку FE мы считаем только по тем задачам, которые решены (вышли из системы), то значение коэффициента у такой команды будет хорошим (высоким), тогда как на самом деле, у команды беда с потоком (его нет, он стоит). Кроме того, в реальной жизни выход из производственной системы у нас не один.
Кроме того, помимо успешного завершения работы над задачей, мы иногда прекращаем работу над задачей. Например, решение задачи упёрлось в какие-то принципиальные ограничения (возможно, внешние), или задача потеряла актуальность (заказчик передумал). Это то, что называется потерями (waste, discard). Опять мы может получить быстрое прохождение задач и, следовательно, высокий FE. Но потери будут огромны, и об эффективности такой системы говорить сложно.
Во-первых, на мой взгляд, это гипотетическая ситуация. Понятно, что за счёт подвигов, каких-то разовых усилий или постоянного ручного экспедирования отдельных задач, производственная система может вести себя таким образом. Но даже в этом случае вряд ли коэффициент эффективности может быть высоким. Ведь каждый из участников производственной системы будет находиться под давлением большого объёма незавершёнки, будут увеличиваться потери, обусловленные переключением контекста. То же самое относится и к сценарию с большими потерями. Ведь на выполнения работ в рамках решения этих задач, уходящих потом в корзину, тоже тратятся силы и внимание. Следовательно, в большинстве реальных кейсов, на скорость решения остальных задач это, скорее всего, будет влиять.
Во-вторых, мы можем изменить способ расчёта, и FE будет учитывать всё, что происходит в производственной системе, включая задачи, которые ещё не дошли до финишной черты. Для этого можно считать вместо LT всё время, которое на момент учёта задача провела в производственной системе. Таким образом, LT будет по-прежнему показывать скорость прохождения задачи. Но наш знаменатель будет учитывать в том числе задачи, которые по той или иной причине не дошли до завершения.  Это и блокеры (на рисунке задача 4), и потери (задача 5), и задачи (2 и 3), которые ещё не решены момент окончания текущего отчётного периода (момент времени T2). Аналогичным образом считаем PT. По всем задачам вне зависимости от состояния и статуса на момент окончания отчётного периода.
Это и блокеры (на рисунке задача 4), и потери (задача 5), и задачи (2 и 3), которые ещё не решены момент окончания текущего отчётного периода (момент времени T2). Аналогичным образом считаем PT. По всем задачам вне зависимости от состояния и статуса на момент окончания отчётного периода.
Единственное, что остаётся определить — как будем относить время обработки (PT) и время нахождения в системе (LT) на задачи-долгожители (пример на рисунке). 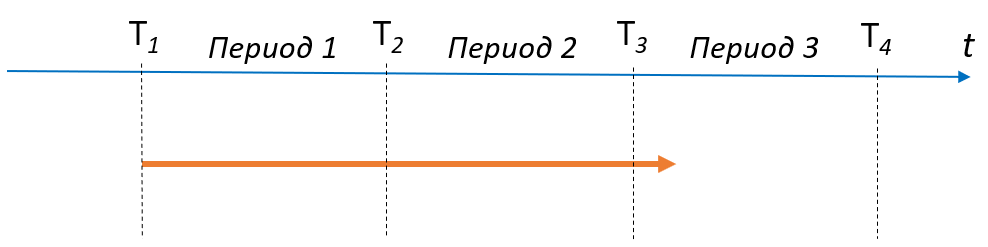 Какое значение попадёт в сумму в знаменателе, например, во втором периоде? T3 – T2 или T3 – T1? Во втором случае мы учитываем длительность периода 1 (T2 – T1) дважды. А при расчёте показателя по окончанию третьего периода — трижды. Зато избегаем ситуации, когда в третьем периоде это слагаемое в знаменателе будет очень маленьким, что может странно исказить показатель FE в лучшую сторону. По-моему, это не столь важно. Особенно, если вспомнить, что FE — это оценка. Выбор в большей степени зависит от того, что нам важнее увидеть: значение такого коэффициента в каждом периоде и динамику по периодам, или равномерность потока в целом.
Какое значение попадёт в сумму в знаменателе, например, во втором периоде? T3 – T2 или T3 – T1? Во втором случае мы учитываем длительность периода 1 (T2 – T1) дважды. А при расчёте показателя по окончанию третьего периода — трижды. Зато избегаем ситуации, когда в третьем периоде это слагаемое в знаменателе будет очень маленьким, что может странно исказить показатель FE в лучшую сторону. По-моему, это не столь важно. Особенно, если вспомнить, что FE — это оценка. Выбор в большей степени зависит от того, что нам важнее увидеть: значение такого коэффициента в каждом периоде и динамику по периодам, или равномерность потока в целом.
В любом случае, проблему с отсутствием учёта зависших и потерянных задач мы таким образом решаем. Причём ценой незначительно усложнения учёта.
Кстати, здесь читатели могут вспомнить обсуждение на нашем портале (1 , 2) метрики процесса управления проблемами, описанной в книге «Управление услугами на основе измерений». В комментариях к упомянутым заметкам было высказано много полезных соображений. В т.ч. мысль о том, что сложно разработать идеальную метрику. А если мы хотим, чтобы она помогала отвечать на все вопросы, то, кажется, что невозможно.
