Продолжение статьи Интересные уроки из аварийных ситуаций.
Adevinta — это международная компания, специализирующаяся на продаже объявлений, которая в 2021 году приобрела бизнес по продаже объявлений eBay. Компания управляет сайтами для покупки и продажи автомобилей, недвижимости и поиска работы. Среди ее брендов — Gumtree (Великобритания), Leboncoin (Франция), OLX и Zap (Бразилия), DoneDeal (Ирландия), Automobile.it (Италия) и Marktplaats (Нидерланды).
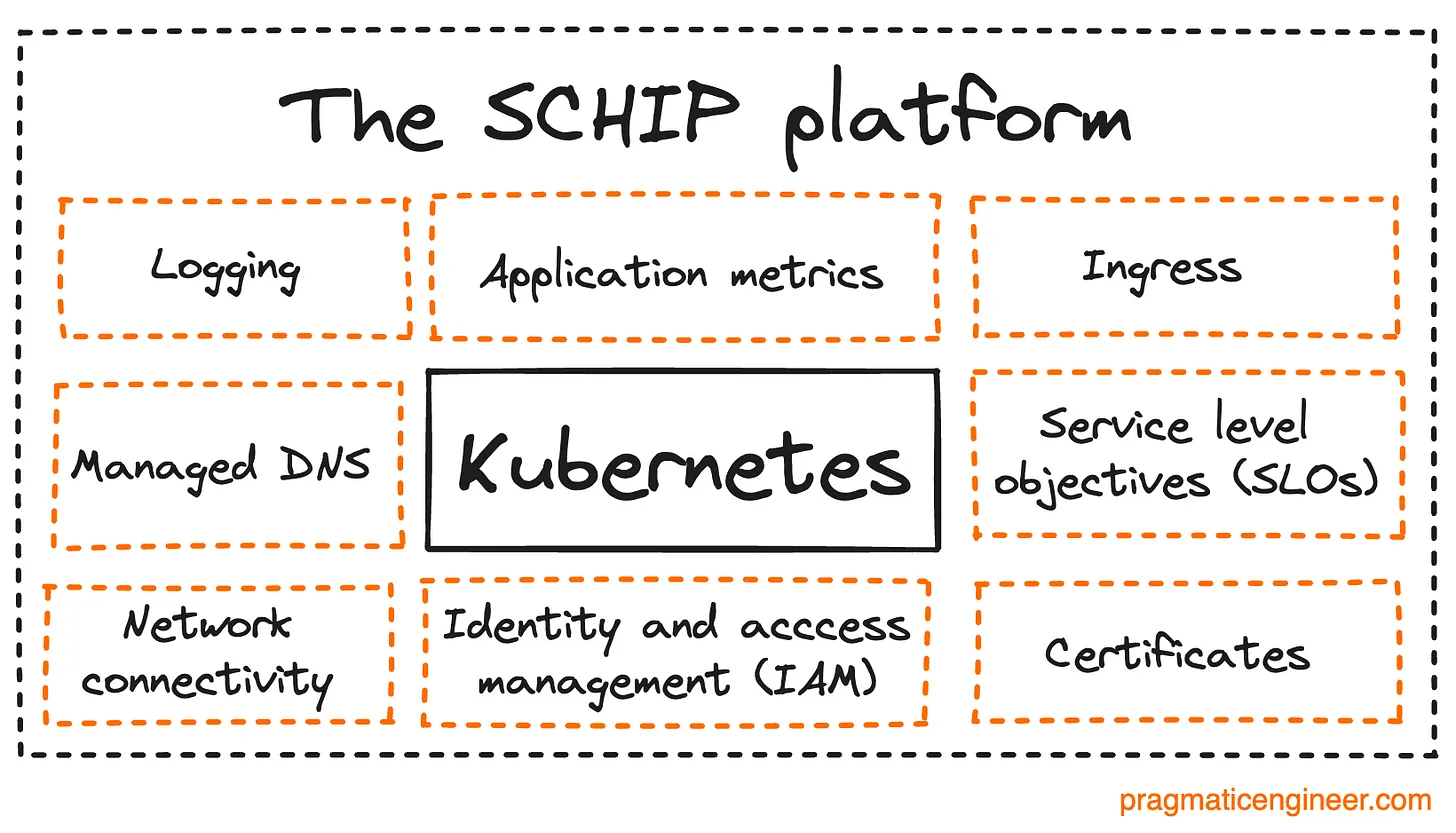
Учитывая, что Adevinta обслуживает десятки локальных торговых площадок, неудивительно, что в компании работает внутренняя команда платформы, которая предлагает общую инфраструктуру, позволяющую продуктовым командам создавать и запускать собственные микросервисы. В Adevinta эта платформа называется SCHIP, и она добавляет такие сервисы, как наблюдение, протоколирование и отслеживание целей уровня сервиса (SLO), а также управление контейнерной инфраструктурой с помощью Kubernetes:
В мае 2023 года одна из команд, занимающихся SCHIP, заметила всплеск количества ошибок типа «5xx» (5** — серверные ошибки, прим.переводчика). Команда объявила об инциденте и начала расследование. С этого момента началось длительное расследование, которое превратилось в нечто похожее на тайну убийства.
Подозреваемый №1: контроллер входа
Входящий трафик означает входящий сетевой трафик и противоположен исходящему трафику или данным. В рамках SCHIP контроллер входа отвечает за прием трафика для всего кластера узлов Kubernetes. Команда заметила некоторые признаки дросселирования процессора — признак того, что некоторые узлы могут быть перегружены и, следовательно, могут отбрасывать пакеты, — и поэтому сначала исследовала эту возможность. Но это расследование оказалось тупиковым.
Но ошибки все равно появлялись, причем, казалось бы, случайным образом, на короткое время и даже тогда, когда у входящего контроллера не было никаких проблем.
Подозреваемый №2: Fluent bit и сетевой уровень
Новая улика позволила предположить, что в ошибке виновата сеть. Это произошло благодаря тому, что команда инженеров обнаружила журнал, в котором было написано: «Агент Fluent Bit перестал обрабатывать журналы».
Fluent Bit — это популярный процессор и форвардер логов с открытым исходным кодом, который используется в Adevinta. Fluent Bit часто используется в облачных и контейнерных средах, а сам проект является частью Cloud Native Computing Foundation (CNCF).
То, что сделало Fluent Bit новым главным подозреваемым, заключалось в том, что наблюдаемая ошибка 5xx произошла на том же узле, что и ошибка Fluent Bit. Команда предположила, что между ними должна быть сетевая проблема. Но после дополнительных исследований это предположение также оказалось тупиковым.
Подозреваемый №3: все возможные подозреваемые
Отслеживание очевидных причин ни к чему не привело, поэтому команда решила поднять расследование на один уровень и создала специальную группу, состоящую из нескольких инженеров. Эта команда создала контрольную панель для отслеживания всей информации, которая могла помочь в поиске проблемы:
— Все запросы 5xx
— Сетевые ошибки
— Метрики использования API
— Изменения метрик подсистемы
— Попадания и пропуски DNS
— Индикаторы уровня сервиса (SLI) задержки DNS
Помогла ли эта контрольная панель? Как ни странно, не помогла. Из обзора инцидента:
«Контрольная панель оказалась еще более запутанной, поскольку каждая отдельная комбинация отображаемых показателей имела смысл до тех пор, пока взятые вместе, они не потеряли его».
Подозреваемый №4: само приложение
Рассмотрение всех показателей в комплексе ни к чему не привело, поэтому команда приступила к изучению конкретного приложения, в котором возникли проблемы. До этого момента команда предполагала, что проблема может затрагивать любое приложение. Однако, изучив детали, они обнаружили, что проблема затрагивает только одно приложение.
Тем самым приложением был прокси-сервер. Этот прокси-сервер находился перед микросервисами, которые выполняли внутренние вызовы. И этот прокси-сервер использовал службу разрешения имен сервисов Kubernetes. Таким образом, это был новый подозреваемый!
Подозреваемый №5: служба разрешения имен сервисов Kubernetes
Служба разрешения имен сервисов Kubernetes — это удобная функция, с помощью которой можно вызывать сервис напрямую. Например, чтобы вызвать конечную точку «api» внутреннего сервиса Search, достаточно обратиться к URL-адресу http://search/api. Служба разрешения имен сервисов позаботится о сопоставлении этого URL с нужным IP-адресом сервиса.
Прокси-сервис вызывает внутренние сервисы, используя эту упрощенную схему API.
Помните подозреваемого №2 — Fluent Bit, у которого были проблемы, связанные с сетью? Оказалось, что Fluent Bit также использовал эти упрощенные URL, и у него также были проблемы, связанные с сетью.
Подозреваемый №6: DNS
Разрешение имени хоста в нужный IP не происходит надежно: это связано с разрешением системы доменных имен (DNS). К этому времени команда инженеров была уверена, что проблема связана с DNS. Было собрано еще больше доказательств, так как команда посмотрела на цель уровня обслуживания (SLO) по задержке DNS и увидела, что для затронутого кластера она находится в красной зоне:
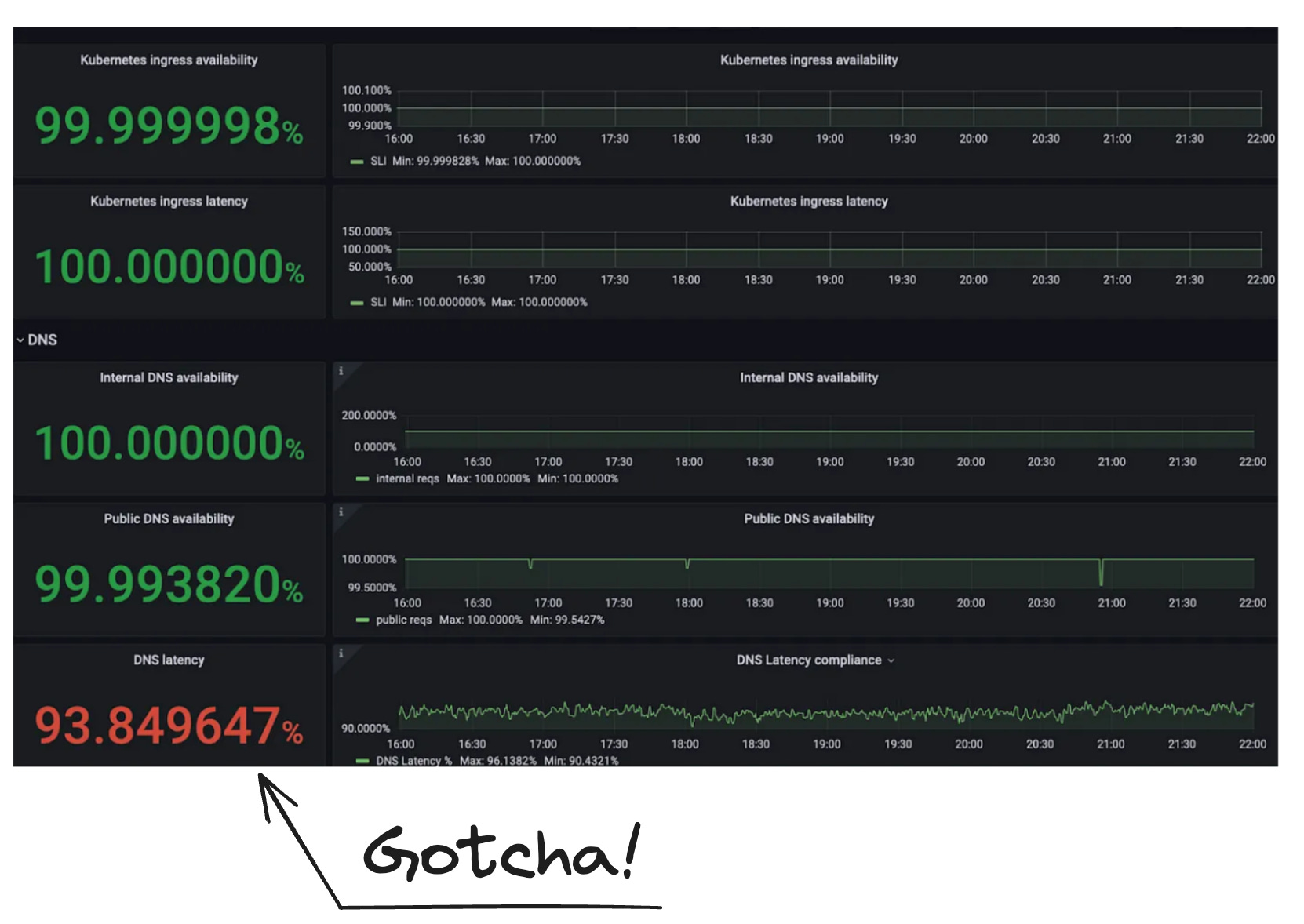
Если бы не было других подозреваемых, и доказательства указывали бы на то, что вероятной причиной является ошибка DNS, было ли это недетерминированное отключение вызвано проблемой DNS? После этого было проведено еще одно подробное расследование, о котором можно прочитать здесь. В итоге: да, виновата внутренняя реализация DNS компании Adevinta, а именно:
- Для DNS-кэша, работающего поверх Dnsmasq, был установлен слишком низкий лимит одновременных DNS-запросов;
- Пропуски DNS-кэша. Сервис DNS-кэша Dnsmasq не кэшировал некоторые внутренние DNS-запросы;
- Переполнение DNS-запросов. Команда обнаружила, что их внутренние DNS-службы были наводнены сотнями запросов в секунду с абсолютно мусорными (несуществующими) DNS-запросами.
В итоге всплеск был вызван сочетанием проблем с DNS-кэшем, переполнением запросов и слишком низким лимитом одновременных DNS-запросов.
Самые важные выводы
Расследование вышеуказанной проблемы заняло целый месяц работы небольшой команды. Я обратился к инженеру по надежности сайта Танату Локеджароенларбу, написавшему этот обзор, и он сказал мне следующее:
1. Важность управления расследованием
Если не организовать работу по расследованию, то можно потратить неопределенное количество времени на решение любой проблемы, особенно нестандартной. Важно работать над одной теорией за раз, концентрируясь на доказательстве ее ошибочности и переходя к следующей теории, пока не будет найдена первопричина».
2. Важность SLI (service level indicators, индикаторов уровня обслуживания)
Наличие нестабильных SLI снижает доверие к ним. В конце концов, нестабильные SLI становятся просто шумом. Наличие надежных SLI обеспечит вас надежными индикаторами, которые укажут вам прямо в сердце проблем.
