Как известно, назначение процесса управления инцидентами – минимизировать негативное влияние на бизнес посредством скорейшего устранения инцидентов. Измерение результативности процесса управления инцидентами чаще всего выполняется двумя метриками: доля своевременно решенных инцидентов и среднее время устранения инцидентов (в разбивке по уровню влияния или приоритету – в зависимости от того, как определяется срок устранения инцидента). Но, строго говоря, ни одна из этих метрик не отвечает на вопрос, насколько удается устранять инциденты скорейшим образом (то есть не просто быстро, а максимально быстро). Можно ли каким-то образом ближе подобраться к ответу на этот вопрос? Попробуем.
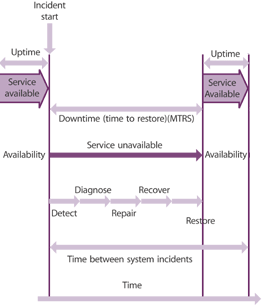 ITIL описывает очень полезный и хорошо применимый на практике аналитический инструмент процесса управления доступностью – Expanded Incident Lifecycle. Он, в частности, позволяет проанализировать, какие стадии выявления и обработки инцидента могут быть оптимизированы с целью сокращения времени решения (а значит повышения доступности ИТ-услуг). Однако к моему сожалению, он недостаточно явно обозначает одну из важнейших стадий обработки инцидента – реагирование на поступивший инцидент (насколько я понимаю, на схеме это где-то между стадиями Detect и Diagnose). Однажды я уже поднимал эту тему, в своей заметке «Управление проблемами и время решения инцидентов», но там мы не затрагивали вопрос измерения времени реакции. Вместе с тем мои оценки (развернутой статистики у меня пока нет) показывают, что в среднем время, которое инцидент проводит в очередях, ожидая, пока им займутся специалисты, как минимум не меньше собственно времени решения (и весьма вероятно даже превышает его). Сокращение времени реакции – один из наиболее очевидных способов сокращения общего времени решения инцидентов. Раз так, давайте научимся его измерять.
ITIL описывает очень полезный и хорошо применимый на практике аналитический инструмент процесса управления доступностью – Expanded Incident Lifecycle. Он, в частности, позволяет проанализировать, какие стадии выявления и обработки инцидента могут быть оптимизированы с целью сокращения времени решения (а значит повышения доступности ИТ-услуг). Однако к моему сожалению, он недостаточно явно обозначает одну из важнейших стадий обработки инцидента – реагирование на поступивший инцидент (насколько я понимаю, на схеме это где-то между стадиями Detect и Diagnose). Однажды я уже поднимал эту тему, в своей заметке «Управление проблемами и время решения инцидентов», но там мы не затрагивали вопрос измерения времени реакции. Вместе с тем мои оценки (развернутой статистики у меня пока нет) показывают, что в среднем время, которое инцидент проводит в очередях, ожидая, пока им займутся специалисты, как минимум не меньше собственно времени решения (и весьма вероятно даже превышает его). Сокращение времени реакции – один из наиболее очевидных способов сокращения общего времени решения инцидентов. Раз так, давайте научимся его измерять.
Собственно, правильно заданный вопрос содержит в себе половину ответа – предыдущими рассуждениями мы весьма точно обозначили, что необходимо измерять, а подходящая математика всегда найдется:
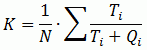
где N – количество назначений инцидентов в заданную функциональную группу;
Ti – время решения i-го инцидента (с момента начала работы над ним);
Qi – время ожидания инцидента в очереди (с момента назначения до начала обработки).
Считаю важным отметить три момента:
- данная метрика нормирована в диапазоне [0; 1] и имеет целевую динамику на возрастание;
- расчет данной метрики лучше выполнять не для инцидента целиком, а для отдельных назначений инцидента в разные группы (поскольку один инцидента может быть последовательно назначен в несколько групп, и даже несколько раз в одну и ту же группу);
- практичнее всего анализировать значение этой метрики именно в разрезе по функциональным группам, чтобы выявить те группы, где время реакции требует сокращения (с последующим поиском шагов, которые такое сокращение могут обеспечить).
Приведенная формула проста для понимания, но не отражает один момент. Дело в том, что инциденты бывают разные – с бОльшим и меньшим влиянием на бизнес. И может быть так, что реакция на более значимые инциденты вполне приемлема, но большой поток инцидентов с малым уровнем влияния занижает среднее время реакции. Чтобы учесть разное влияние инцидентов, можно выбрать один из двух путей:
- выполнять расчет данной метрики в разбивке по уровням влияния / приоритетам;
- привести формулу к взвешенному среднему, используя в качестве веса Wi уровень влияния или приоритет инцидента:
![]()
Считайте на здоровье. И делитесь результатами – мне очень интересно набрать статистику, подтверждающую или опровергающую мои оценки.

Если я не ошибаюсь, правильной стратегией для минимизации этой метрики (если не думать о весах приоритетов) будет — «всегда в первую очередь браться за самый быстрорешаемый инцидент». Выглядит довольно логично.