Продолжаем публикацию находок по измерению процессов управления ИТ, начатую в заметке «Измеряем Problem management».
Примеров метрик по процессу управления инцидентами множество. Пожалуй, это самый изученный с точки зрения измерения процесс ITSM. Однако в очередном проекте мы в который раз столкнулись с вопросом: как реализовать метрику, которая бы показывала долю ответственности заданной группы поддержки в нарушении сроков обработки инцидентов. Вопрос давний и непростой. Сложности связаны с тем, что в обработке одного инцидента могут принять участие несколько групп (за счёт функциональной эскалации). Традиционное решение «вешать просрочку» на последнюю группу, обрабатывавшую инцидент, обладает рядом очевидных минусов. В самом деле, эта группа могла получить инцидент уже просроченным, за пять минут до наступления срока и так далее.
Пришло решение использовать в качестве одного из KPI групп поддержки метрику, значение которой рассчитывается по формуле:
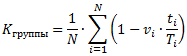
где Кгруппы – KPI группы по своевременности обработки инцидентов;
N – общее число инцидентов, в обработке которых участвовала данная группа, за период;
vi – 0 или 1. 0, если i-тый инцидент решён в срок. 1, если инцидент просрочен;
ti – время обработки i-того инцидента силами данной группы, включая время реакции на назначение (время с момента назначения инцидента до переназначения в другую группу или окончания работы);
Ti – общее время обработки i-того инцидента (от регистрации до решения).
Поясню смысл формулы. За каждый инцидент, в обработке которого поучаствовала какая-то группа, она получает балл от 0 до 1. 1 – идеальный вариант, инцидент решён в срок. 0 – наихудший вариант, срок нарушен и ответственность за это целиком лежит на данной группе. Промежуточные значения соответствуют нарушению срока в результате работы нескольких групп. Причём штраф распределяется по группам пропорционально их доле в общем времени обработки просроченного инцидента. Значение метрики формируется усреднением баллов по всем инцидентам, прошедшим через данную группу. Оно также изменяется строго в пределах [0; 1]: 1 – отлично, 0 – наихудший результат. Поэтому для него легко установить целевое значение и использовать полученный KPI для контроля, а также стимулирования работы старших групп поддержки.
Предложенная метрика обладает рядом «правильных» мотивационных эффектов. В частности, она стимулирует скорее обрабатывать даже те инциденты, которые были переданы в группу после нарушения срока. Кроме того, метрика несёт в себе правильный для процесса управления инцидентами посыл, что нарушение срока решения инцидента – это не столько вина отдельной группы (стрелочника), сколько поставщика услуг в целом. Каждая группа вносит свой вклад и в нарушение сроков, и в скорейшее решение инцидента. Поэтому для повышения уровня поддержки необходимо организовывать сотрудничество групп поддержки.
В литературе не встречал, поэтому решил опубликовать. Критикуйте, пожалуйста. Пользуйтесь на здоровье.
P.S. Примечательно, что эта метрика естественным образом «масштабируется» с уровня отдельной группы до уровня всего процесса. В самом деле, будем укрупнять группы поддержки до предельного состояния, когда единственная группа поддержки – это весь персонал поставщика услуги. В этом случае ti становится равным Ti и формула принимает привычный вид метрики «доля инцидентов, решённых в срок»:
.png)
P.P.S. Предложенная метрика также легко может быть модифицирована для учёта того, как сильно просрочены инциденты (если нам не всё равно, был ли срок превышен на одну минуту или в несколько раз). Для этого каждому инциденту можно присвоить вес wi. Вес равен 1, если инцидент решён в срок. Если же срок превышен, то вес может определяться, например, как отношение фактического времени решения инцидента Ti к установленному сроку. Тогда формула для расчёта метрики примет вид:
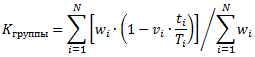
Чтобы лучше её осознать, введём обозначение:
![]()
Тогда метрика принимает привычный вид взвешенного арифметического среднего:
.png)
Где вес wi определяет, на сколько (как сильно) был превышен срок обработки i-того инцидента, а рейтинг ri – в какой степени ответственность за просрочку лежит на данной группе.
P.S.P.S. Чтобы предотвратить "футбол" (быстрое, бездумное перекидывание инцидентов в другие группы) плюс к предложенной здесь метрике своевременности нужна вторая метрика – результативности. Она также считается несложно, о ней напишу в отдельном топике. Вместе метрики своевременности и результативности образуют сбалансированную пару KPI для оценки деятельности групп поддержки.
ДОПОЛНЕНИЕ
По итогам обсуждения с Павлом Солоповым (за что ему спасибо) предлагаю альтернативный алгоритм расчёта метрики в P.P.S. Основное отличие – сокращение влияния действий других групп на значение метрики для заданной группы (за счёт нормировки не на общее время обработки Ti, а на срок решения инцидента Ti0).
Формула сохраняет вид взвешенного среднего в P.P.S, меняется только определение операндов. Вес wi равен 1, если инцидент решён в срок. Если срок превышен, то вес равен отношению времени обработки инцидента силами данной группы ti к сроку решения инцидента Ti0 (таким образом, вес может быть и больше, и меньше единицы), но не меньше 1.
Рейтинг ri определяется выражением:
.png)
Нормировка [0; 1] сохранена.

У себя в блоге я разместил перевод статьи «Показатели работы служб поддержки», автор -Даниэл Вуд (Daniel Wood)
Руководитель исследования
SDI (Service Desk Institute)