 В любой области существуют понятия, которые известны почти всем. Например, я уверен, что все посетители нашего портала слышали, хотя бы разок, про такую штуку, как цикл Деминга (он же PDCA-цикл). Ничего сложного в PDCA в общем-то нет – четыре шага: Планируй, Выполняй, Проверяй, Корректируй. Однако недавно я задумался над вопросом, который раньше, почему-то, не приходил мне в голову: «А чем, собственно, отличаются шаги цикла Act и Plan?».
В любой области существуют понятия, которые известны почти всем. Например, я уверен, что все посетители нашего портала слышали, хотя бы разок, про такую штуку, как цикл Деминга (он же PDCA-цикл). Ничего сложного в PDCA в общем-то нет – четыре шага: Планируй, Выполняй, Проверяй, Корректируй. Однако недавно я задумался над вопросом, который раньше, почему-то, не приходил мне в голову: «А чем, собственно, отличаются шаги цикла Act и Plan?».
И ведь действительно: сначала мы планируем (Plan), затем выполняем (Do), далее проверяем (Check). А что дальше? Ищем причины расхождений? Нет, это Check. Изменяем наш план? Но это же Plan! Так в чем же смысл этого четвертого шага?
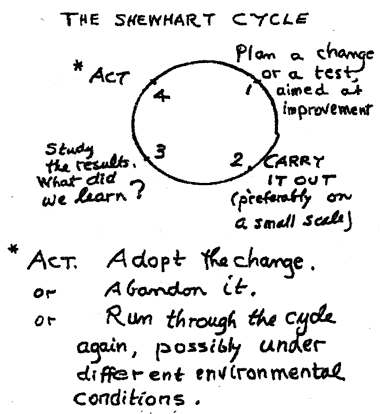 Вот здесь написано, что сам Деминг при описании цикла (который он, кстати, называл циклом Шухарта) говорил, что шаг Act может заключаться либо в принятии изменений для исправления расхождений, выявленных на стадии Check, либо в игнорировании этих расхождений, либо в повторном запуске цикла. Насколько я понимаю, первые два варианта ведут к завершению цикла, а в последнем случае шага Act как такового не существует – он заменяется повторным выполнением P-D-C. Иными словами шаг Act заключается в ответе на вопрос: «Что же делать дальше?». Чтобы сформировать более понятную картинку, попробуем разобрать пример.
Вот здесь написано, что сам Деминг при описании цикла (который он, кстати, называл циклом Шухарта) говорил, что шаг Act может заключаться либо в принятии изменений для исправления расхождений, выявленных на стадии Check, либо в игнорировании этих расхождений, либо в повторном запуске цикла. Насколько я понимаю, первые два варианта ведут к завершению цикла, а в последнем случае шага Act как такового не существует – он заменяется повторным выполнением P-D-C. Иными словами шаг Act заключается в ответе на вопрос: «Что же делать дальше?». Чтобы сформировать более понятную картинку, попробуем разобрать пример.
Допустим, мы занимаемся совершенствованием процесса управления инцидентами, который функционирует в нашей компании и, проведя в очередной раз опрос пользователей, мы узнали, что большинство из них не довольны тем, что техническая поддержка очень долго исправляет возникающие сбои. Т.е. основная масса даже самых элементарных запросов выполняются очень долго. Тут-то мы и начинаем раскручивать PDCA-карусельку.
Планирование. Для того, чтобы решить возникшую задачу, мы вспоминаем про такой полезный инструмент, как Expanded Incident Lifecycle. Разбив время жизни инцидента на определенные этапы, и измерив среднюю продолжительность каждого из них, мы приходим к выводу, что довольно большую долю времени занимает нахождение инцидента в очереди. Чтобы с этим справиться мы просим всех специалистов при обнаружении «простых» инцидентов решать их сразу, откладывая решение «сложных» инцидентов. Для контроля же мы можем использовать метрику скорости реакции, например вот такую.
Выполнение. На протяжении некоторого периода времени мы работаем по придуманной схеме. Если наше предположение верно, то ситуация должна улучшиться.
Проверка. По истечении некоторого времени мы проверяем, улучшилась ли ситуация. Для этого мы опять проводим опрос пользователей, и выясняется, что хоть количество недовольных и сократилось, в ряде случаев (иногда очень серьезных) пользователи ждали решения сбоев чрезмерно долго. Причиной такой ситуации оказался тот факт, что из-за большого количества «простых» инцидентов, «сложные» порой откладывались в сторонку и ждали очень долго.
Корректировка. Поскольку проведенное улучшение не устраивает нас в полной мере, мы принимаем решение запустить цикл заново и учесть все находки первого прогона цикла. В этом заключается шаг Act на данном этапе.
Планирование 2. Зная проблему «сложных» и «простых» инцидентов мы принимаем решение выделить подгруппу сотрудников, которая будет заниматься решением только «простых» инцидентов. Для них можно поставить в качестве KPI количество решенных инцидентов (в связке с количеством возвращенных).
Выполнение 2. Работаем еще некоторое время по новой схеме.
Проверка 2. Через некоторое время опять опрашиваем пользователей и видим, что неудовлетворенность скоростью устранения сбоев практически исчезла.
Корректировка 2. Поскольку результаты наших улучшений нас устраивают, шаг «корректировка» будет заключаться в завершении цикла без каких-либо дополнительных изменений.
Прошу не обращать внимания на некоторую надуманность примера. Жизнь, конечно же, немного более сложная и многогранная. Тем не менее этот пример неплохо демонстрирует мое текущее понимание того, что такое шаг Act.
А вы согласны с таким объяснением? Если нет, расскажите свою версию.
UDPATE: Переосмыслил для себя понятие цикла Деминга. Теперь считаю верной вот такую картинку. Спасибо, коллеги!

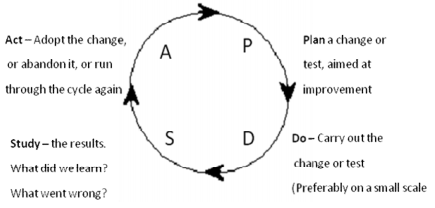
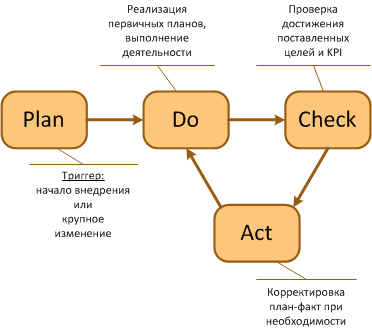
Попробуйте переставить буквы местами: apdc
a-оценка рисков,оценка соответствия,оценка достижения целей,…
P-планирование обработки рисков, приведения к соответствию, план работы подразделения, …
D- реализация планов
с- контроль и мониторинг рисков (kri), kpi,..
Как считаете, в таком исполнении «а» нужен? 🙂