Последнее время я все больше укрепляюсь в давно блуждающей в моей голове и довольно еретической мысли: классический показатель доступности малопригоден для измерения и оценки доступности ИТ-услуг в реальном мире. И в ряде случаев от него можно легко отказаться. Эти случаи касаются в первую очередь измерения доступности услуг типа «ИТ-обеспечение бизнес-процессов» (фактически речь идет об ИТ-доступности бизнес-процессов). Попробую обосновать и буду рад услышать возражения.
Полагаю, всем читателям портала знакома формула:
Availability = (AST — DT)/AST,
где AST – согласованное время предоставления услуги, DT – сумма простоев за период.
А также, вероятно, знакомы сложности ее применения:
Первая сложность связана с обсуждением показателя. Доступность определена как 99,9%. Вроде неплохо. Но 0,1% в год равен почти 9 часам. А в месяц – это почти 45 минут. А в неделю – чуть более 10 минут. Так какие 99,9% имел в виду заказчик? А сервис-провайдер?
Однако значительно более существенен следующий нюанс: показатель довольно неточно отражает негативное влияние на бизнес. Что если все без малого 9 часов за год случились разом? Или услуга становилась недоступна потребителям по две минуты, но 15 раз за один день? Как это будет выражено в процентах?.. Поэтому, например, ITIL вводит такие показатели, как MTRS, MTBF, MTBSI.
Однако предлагаю вернуться в начало координат и задаться вопросом, а зачем мы вообще вводим показатели доступности? Почему бизнес предъявляет требования к доступности услуг? Почему сервис-провайдер должен обеспечивать высокую доступность и отчитываться по ее фактическим значениям? Ответ прост: бизнес несет потери вследствие простоев ИТ-услуг. Значит, идеальным для бизнеса показателем доступности, вероятно, была бы метрика «Потери вследствие простоев ИТ-услуг»?
Сильно выручила бы такая метрика и сервис-провайдера. Ведь это готовый ответ на вопрос о бизнес-рисках, связанных с нарушениями ИТ-доступности. И, следовательно, у сервис-провайдера появляется возможность:
- более прозрачно транслировать требования доступности бизнес-процессов к ИТ-инфраструктуре;
- более обоснованно принимать решения по мерам, направленным на повышение надежности и отказоустойчивости ИТ-систем;
- более обоснованно оценивать успешность мер по итогам их реализации.
Но, конечно, произвести расчет такой метрики сложно, порой невозможно. Таким образом, мы должны определить другие показатели, не забывая о том, что в совокупности они должны нести информацию о бизнес-влиянии (фактическом или потенциальном).
От чего зависят потери бизнеса вследствие простоев?
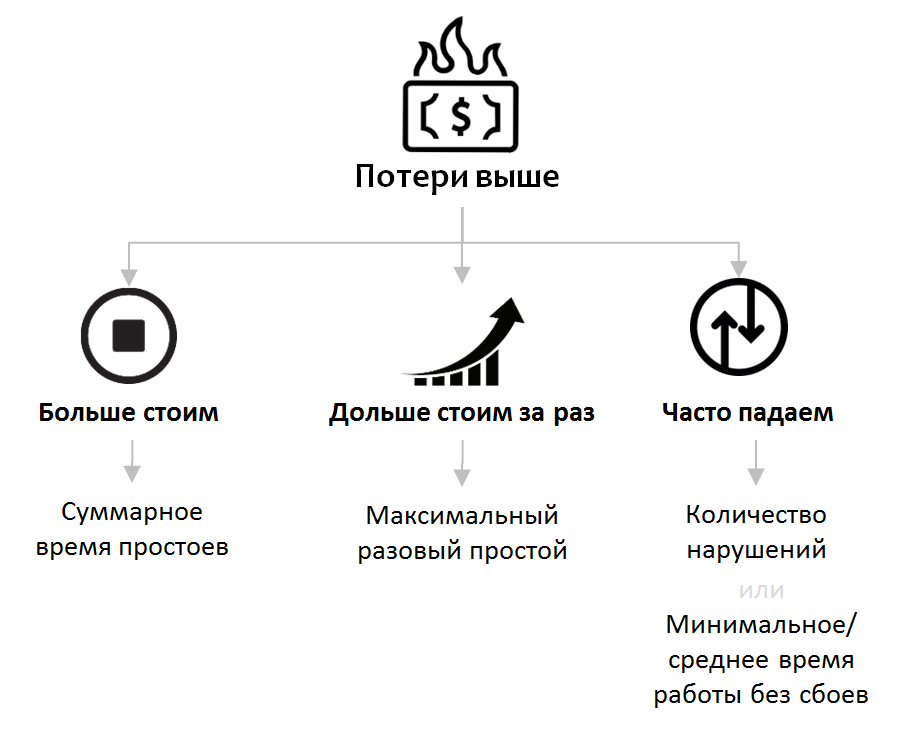
- Чем меньше за отчетный период услуга была в uptime, тем больше потери. Введем показатель «Суммарное время простоев».
- Чем дольше разовый простой, тем больше потери. Нередко потери не являются постоянной во времени величиной и зависят от длительности прерывания экспоненциально. В первый отрезок времени ущерб складывается из несовершенных транзакций, потерь продуктивности персонала и затрат на восстановление, но с определенного момента длительный простой угрожает бизнесу штрафами, санкциями, уроном репутации и так далее. Введем показатель «Максимальный разовый простой».
- Ряд бизнес-процессов, напротив, «чувствительны» не к единичным длительным простоям, а к частым прерываниям. Это особенно важный фактор для процессов, в рамках которых происходят длительные вычисления, которые в случае прерывания требуется перезапускать. Таким образом, должно быть обеспечено как можно меньшее количество прерываний за период. Введем показатель «Количество нарушений».
Альтернативной (или дополнительной) метрикой, отражающей тот же аспект, но с акцентом на периоде спокойной работы пользователей, может быть показатель «Минимальная (или средняя) продолжительность работы без нарушений».
Представленные показатели в совокупности, кажется, отражают характер того, как бизнес несет потери вследствие простоев ИТ-услуг. Поэтому далее остается только известным способом выполнить нормирование и агрегирование. Да, полученный показатель будет также выражен в процентах, но это будут уже совсем другие проценты.
При этом не обязательно для каждой ИТ-услуги использовать все три (или четыре) метрики. В зависимости от того, чувствителен ли бизнес к частым нарушениям данной ИТ-услуги или, напротив, для него критичны длительные разовые нарушения, часть показателей могут быть опущены или включены в расчет с меньшим весом.
От представленных метрик можно легко перейти к известным MTRS, MTBF, MTBSI и, конечно, классическому показателю доступности. Но, на мой взгляд, предложенный набор скажет заказчику и сервис-провайдеру несколько больше о бизнес-влиянии нарушений ИТ-доступности. Или нет?
Отчаянно нуждаюсь в возражениях. Почему от классического показателя доступности услуги, выраженной в процентах, ни в коем случае нельзя отказываться? Есть ли такой показатель в ваших отчетах? О чем и кому он говорит?

>> Почему от классического показателя доступности услуги, выраженной в процентах, ни в коем случае нельзя отказываться?
Можно. Но этот показатель — "попса". Он повсюду, к нему привыкли.
Поэтому отказаться можно там, где Бизнес может чётко сформулировать одну (или все три) из предложенных вами метрик. Ну а если SLA носит "статусный" характер, то вполне себе подойдёт. Это даже не вдаваясь в подробности, как считается этот %, это отдельная тема 🙂