Автор статьи «Рекомендуемые пять метрик надёжности связанных со среднем временем» («5 Mean-Time Reliability Metrics To Follow») недавно опубликованной на портале DevOps.com пишет о том, что большинство специалистов на ролях DevOps или SRE знакомы с метрикой MTTR (mean-time-to-recovery — среднее время восстановления) {также часто называемой MTRS — Mean Time to Restore Service (среднее время восстановления услуги)}. Это широко используемый индикатор, на основе которого можно судить о возникновении узких мест в работе поддержки. Иногда он используется для демонстрации того, насколько хорошо предоставляется платформа {услуга/продукт} в целом. Но фокусировка только на этой метрике не позволяет получить полезных деталей. Поэтому автор предлагает следующий набор так называемых MTTx метрик.
Mean-Time-To-Detect
Среднее время обнаружения — сколько времени в среднем требуется для обнаружения инцидента.
Mean-Time-To-Acknowledge
Среднее время реакции — сколько времени требуется человеку, чтобы осознать инцидент и начать действовать в соответствии с ним.
Mean-Time-To-Recover
Среднее время восстановления — это среднее время, необходимое для введения временного решения после обнаружения инцидента. Например, если в определенном регионе происходят сбои, инженеры могут временно перенаправить трафик на более стабильный сервер. Это не постоянное исправление, но система восстанавливается, и операции, как правило, не затрагиваются. Это помогает поддерживать статус-кво, пока разрабатывается, тестируется и применяется более постоянное решение.
{прим.ред. Очевидно, такой путаницы с терминологией (recover—repair—resolve), на которую, кстати, указывает сам автор статьи, не возникает, если разобраться с понятиями. Например, здесь наиболее очевидна польза от разделения инфраструктурных и сервисных инцидентов (с контролем связи между ними). Мы, решив сервисный инцидент, восстанавливаем необходимый уровень предоставления услуги. Тогда как сбойный элементы инфраструктуры, возможно, ещё не найден и не восстановлен, т.е. инфраструктурный инцидент всё ещё не решён. Никакой путаницы. Нужно лишь чётко зафиксировать, о каком инциденте идёт речь, с каким объектом связан инцидент}
Mean-Time-To-Repair
Среднее время исправления — это среднее время, необходимое для окончательного исправления системы после обнаружения инцидента. Чтобы система считалась полностью исправленной, она должна не просто работать, а работать надежно.
Mean-Time-To-Resolve
Среднее время разрешения — среднее время между возникновением инцидента и моментом полного разрешения ситуации. Произведено не только исправление системы, но и выполнены все остальные связанны работы (всё, включая необходимую документацию, обновлено; работа в штатном режиме восстановлена; все проинформированы; уроки извлечены; и разработаны планы реакции на подобные инциденты в будущем).
Отслеживание каждой из приведённых пяти метрик позволяет более чётко идентифицировать, в какой части работ по устранению инцидентов возникают сложности. Мы поздно обнаруживаем (и нужно что-то делать с мониторингом)? Мы медленно передаём информацию об обнаруженных инцидентах (нужно повышать эффективность коммуникация и улучшать время реакции)?
Понятно, что нужно учитывать ограничение средних значений. В реальной жизни нам, скорее всего, понадобится отслеживать отклонения от среднего.
Основной же сложностью будет договориться о чётком определении моментов времени, в которые начинается и заканчивается отсчёт значений соответствующих метрик. Это не всегда просто. Например, мы обычно знаем, когда восстановлена система. Но когда потребитель смог продолжить работу, прерванную инцидентом, или, как минимум, когда потребитель подтвердил восстановление?
От редакции осталось добавить, что схожая идея описывается в библиотеке ITIL моделью «расширенного жизненного цикла инцидента» (expanded incident lifecycle). Например, в книге «Проектирование услуги» (Service Design) ITILv3 в редакции 2007 года есть такая иллюстрация (и соответствующее описание [термины «detection», «diagnosis», «repair», «recovery» и «restoration» официально были переведены «обнаружение», «диагностика», «исправление», «восстановление», «возобновление» соответственно]).

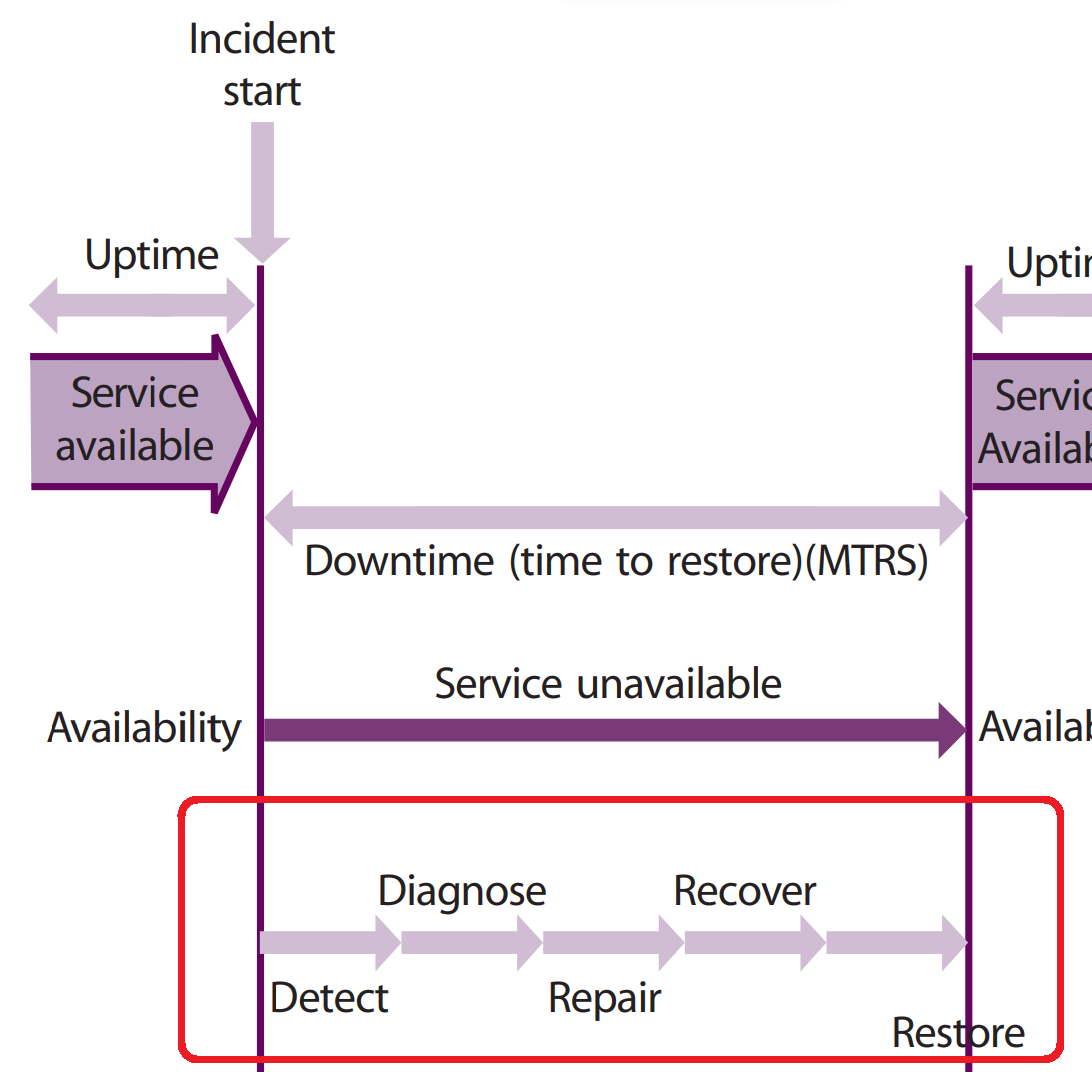
Некоторые детали отличаются. Но в целом похоже, правда же?

Брат-близнец, на мой взгляд!