 Назначение процесса управления инцидентами – скорейшее устранение нарушений в предоставлении услуг. Если сервисные запросы достаточно выполнять своевременно (в установленный срок), то инциденты надо решать как можно быстрее. Но KPI процесса управления инцидентами традиционно основаны именно на своевременности. Думал на тему, как можно мотивировать решать не просто вовремя, а как можно быстрее. Результаты размышлений дискуссионные, хочу мнения коллег.
Назначение процесса управления инцидентами – скорейшее устранение нарушений в предоставлении услуг. Если сервисные запросы достаточно выполнять своевременно (в установленный срок), то инциденты надо решать как можно быстрее. Но KPI процесса управления инцидентами традиционно основаны именно на своевременности. Думал на тему, как можно мотивировать решать не просто вовремя, а как можно быстрее. Результаты размышлений дискуссионные, хочу мнения коллег.
Собственно, «лобовой» подход прост. Для инцидентов, помимо своевременности, вводим KPI на среднее время решения. Затем для своевременности и среднего времени решения определяем целевые и граничные значения, объединяем оба показателя подходящим алгоритмом агрегирования, и задача решена. Но среднее время решения инцидентов – это очень средняя температура по очень большой больнице. Поэтому такой подход может оказаться довольно грубым. Можно ли аккуратнее?
Попробуем. Например, для каждого норматива на устранение инцидента, помимо максимально допустимого времени восстановления (Tmax), можно задать еще один показатель – нижнюю границу по времени, до которой инцидент практически не оказывает на бизнес значимого влияния (Tmin), Tmin < Tmax. Например, инцидент гарантированно должен быть устранен за 4 часа (Tmax = 4,0), но простой менее 30 минут незаметен (Tmin = 0,5). Тогда рейтинг, который поставщик услуг «получает» за решение i-го инцидента, можно определить формулой:
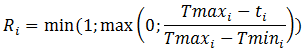
где ti – фактическое время устранения инцидента. То есть решили быстрее, чем Tmin – отлично, 100%. Не уложились в Tmax – очень плохо, 0%. А между Tmin и Tmax – промежуточное значение от 0 до 1. Причем, чем ближе к максимальному времени восстановления, тем ближе к 0. А чтобы у исполнителей не пропадал интерес заниматься просроченными инцидентами, аналогично формуле 7 из книжки итоговый KPI считаем взвешенным средним с весами
![]()
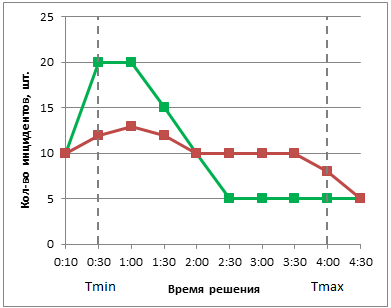 Чтобы разобраться с тем, что у нас получилось, рассмотрим два примера (см. рисунок). В обоих случаях за период было решено 100 инцидентов, нормативы определены как в примере выше (4 часа и 30 минут). В обоих случаях было просрочено только 5%, то есть KPI своевременности решения одинаков и равен 95%. Но в зеленом варианте инциденты в среднем решались быстрее, чем в красном. И расчет по представленным формулам для зеленого варианта дает значение 67%, для красного – 56%. Вроде работает.
Чтобы разобраться с тем, что у нас получилось, рассмотрим два примера (см. рисунок). В обоих случаях за период было решено 100 инцидентов, нормативы определены как в примере выше (4 часа и 30 минут). В обоих случаях было просрочено только 5%, то есть KPI своевременности решения одинаков и равен 95%. Но в зеленом варианте инциденты в среднем решались быстрее, чем в красном. И расчет по представленным формулам для зеленого варианта дает значение 67%, для красного – 56%. Вроде работает.
Однако работает непривычно: решение впритык к Tmax дает рейтинг близкий к 0, и привычка возмущается: «Секундочку, но ведь мы успели!» (в традиционном показателе своевременности рейтинг у таких инцидентов был бы 1). Но вот, что я думаю по этому поводу. Обычно норматив на время решения, скажем в 2 часа, выбирается как некоторый компромисс между ожиданиями бизнеса (полчаса, иначе бизнес пропал!) и осторожными оценками ИТ (4 часа, иначе придется напрягаться). Так может вместо компромисса, который может быть непривлекателен ни для одной из сторон, просто фиксировать Tmin (нужно бизнесу) и Tmax (с запасом, с учетом ограничений ИТ)?
Еще один любопытный момент применения такого KPI – поставщику невыгодно допускать инциденты. По крайней мере, те, которые не могут быть в массе своей решены в пределах Tmin, то есть оказывают значимое влияние на бизнес (в то время как в традиционном варианте достаточно успеть их решить в рамках Tmax, то есть вполне можно получить KPI=1 при существенном влиянии инцидентов на бизнес). А значит этот KPI может быть более удобен при построении комплексных системы мотивации ИТ, поскольку он касается не только поддержки (быстро поднимаем), но и доступности ИТ-систем (не допускаем падений).
Хочу обсуждения с коллегами. Кто участвует?

Мне больше нравится общение через универсальный инструмент — стоимость. Есть стоимость потерь от простоя бизнесс процесса, вызванного недоступностью ИТ сервиса(включая его недостаточную производительность, что тоже есть недоступность сервиса о котором договорились в SLA ). Потери прямо пропорционально связанны с временем простоя(восстановления). Есть затраты на восстановление сервиса и они обратно пропорциональны времени простоя(восстановления).(это затраты не только на деятельность службы сервис деска, но и затраты на повышение отказоустойчивости ИТ системы в целом. В принципе можно создать систему с временем простоя 0,0000….01 секунды, но её стоимость будет в сотни раз превосходить возможные потери от простоев). Достижение минимума потерь от простоя и затрат на восстановление и должно дать требуемое время, которое и надо выбирать за целевой показатель. Проблема в том, что бизнес в подавляющем большинстве случаев не может расчитать потери от простоев.