Недавно в рамках внутреннего обсуждения услышал про дискуссию, случившуюся на одном из курсов у коллеги. И хотя речь шла о, казалось бы, простейшем понятии – инциденте, спор вышел жарким. Жалею, что мне не довелось поучаствовать. Компенсирую текстом ниже 😊
О чём спор
Является ли инцидентом любое отклонение в той части ИТ-экосистемы (что-то не работает или работает медленнее, чем требуется, и т.д. и т.п.), за которую мы отвечаем? Или нет?
Что говорится в умных книгах
Определение понятия «инцидент» в предыдущей версии ITIL (ITIL v3) звучало так:
«Незапланированное прерывание или снижение качества ИТ-услуги. Сбой конфигурационной единицы, который еще не повлиял на услугу, также является инцидентом, как, например, сбой одного диска из массива зеркалирования» [ITIL Service Operation, официальный перевод словаря терминов и аббревиатур ITIL]
В новой версии ITIL определение звучит немного иначе:
«Незапланированное прерывание или снижение качества услуги» («An unplanned interruption to a service or reduction in the quality of a service» [ITIL 4, Руководство по практике управления инцидентами])
Оставим за рамками данного обсуждения то, что в ITIL 4 говорится не про ИТ-услугу, а про услугу вообще. Но, помимо этого, разница определений только в одном – второе предложение определения в предыдущей версии, где говорится об элементах, из которых состоит услуга, в новой версии в определении отсутствует.
Эту же разницу мы можем наблюдать и формулировках назначения управления инцидентами (процесса и практики, соответственно).
«Восстановление нормальной работы услуги в кратчайшие сроки и минимизация негативного влияния на работу бизнеса, гарантируя тем самым поддержание согласованного уровня качества услуги. «Нормальная работа услуги» определяется как рабочее состояние, при котором услуги и конфигурационные единицы работают в пределах согласованных уровней» [ITIL, Service Operation, 4.2.1.1]
и
«Минимизация негативного влияния инцидентов за счёт скорейшего восстановления нормальной работы услуги» [ITIL 4 Incident Management Practice Guide, 2.1]
Означает ли это, что теперь «согласно новой версии ITIL» инцидентом является только нарушение нормального предоставления услуги? Нет. Там же, в руководстве по управлению инцидентами мы видим следующий текст.
«Практика управления инцидентами не ограничивается качеством услуги, воспринимаемым пользователями. Она включает в себя восстановление нормальной работы услуг и ресурсов, даже когда их сбой или отклонение не видны потребителям услуг. В этом случае нормальная работа может быть определена в технических спецификациях услуг или конфигурационных единиц» [Incident Management ITIL 4 Practice Guide, 2.1]
Получается, что все ключевые смыслы сохранились и в ITIL 4.
Ну, так инцидент, или нет?
Остаётся разобраться только в следующем. Любое ли отклонение в поведении того или иного компонента, из которых состоит услуга, является инцидентом? И, соответственно, любое ли такое отклонение требует скорейшего устранения?
Допустим, мы строим отказоустойчивую конфигурацию. RAID-массив, кластер серверов. Что угодно, состоящее из какого-то числа дублирующих элементов. Например, систему электропитания, состоящую из объединения большого числа батарей. Пусть в нашем примере эта система электропитания обеспечивает работу программно-аппаратного комплекса, автоматизирующего определённый бизнес-процесс. Предоставляемая нами услуга, таким образом обеспечивает автоматизацию данного бизнес-процесса. И одним из элементов этой услуги является описанная система электропитания.
Выход их строя одного из элементов меняет характеристики услуги? – Да. Даже если электропитание благодаря дублированию элементов не прервётся и не изменит основных своих характеристик (ток, напряжение и их равномерность), меняется надёжность всей системы. С выходом из строя каждого последующего элемента (при условии, что деградации электропитания не происходит) происходит увеличение вероятности этой самой деградации. Если количество вышедших из строя элементов превысит значение, определённое для данной конфигурации, то произойдёт деградация (вплоть до прерывания) электропитания и далее услуги. Собственно, на минимизацию этого риска и направлено дублирование в данном случае. И чем более критичной будет услуга для бизнеса, тем при прочих равных больше мы будем пытаться снизить вероятность деградации, наращивая избыточность.
Более того, наращивая избыточность, мы можем довести ситуацию до состояния, когда выход из строя одного, двух, трёх… элементов все ещё не приводит к увеличению риска деградации услуги выше допустимого для нас предела. В таком случае для нас нормальной будет ситуация, когда какое-то количество элементов отказоустойчивой конфигурации не работают поскольку вышли из строя. Это запланированное, проектируемое поведение системы. Т.е. такое поведение системы является нормой. Той самой нормой, о которой говорится в определении термина «инцидент» (см. выше).
Соответственно, устранение подобных отказов может выполняться как плановые работы, работы по запросу. В них нет никакого «скорейшим образом» (о чём говорится в назначении управления инцидентами).
Разумеется, дублирование – это дополнительные затраты. И чем больше мы можем позволить себе затрат на увеличение дублирования (при прочих равных), тем большее количество неработающих компонентов мы воспринимаем как норму. И, соответственно, не работаем с ними как с инцидентами.
Причём дело не только в количестве вышедших из строя компонентов, но и в том, в каком месте конфигурации вышел из строя компонент (в том числе поэтому в предыдущем абзаце есть оговорка «при прочих равных»).
Возьмём для примера простейший массив из четырёх дисков в конфигурации RAID 1+0 (чередование [stripe] на базе двух зеркал [mirror]) – рис.1. Для простоты будем считать, что пока дисковый массив выполняет свою функцию хранения данных, всё хорошо, и нам неважно, каков уровень отказоустойчивости или насколько изменились риски отказа массива. Иными словами, в этом примере наша цель – «чтобы работало».
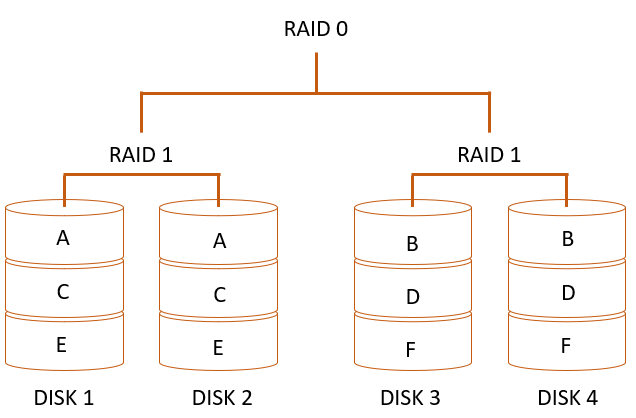
Также для простоты примера пренебрежём возможным изменением быстродействия – предположим, что скоростные характеристики не меняются при выходе из строя каких-либо из дисков данного массива. Тогда выход из строя одного диска (например, диска 1 на рис.2) не меняет характеристики работы RAID-массива.
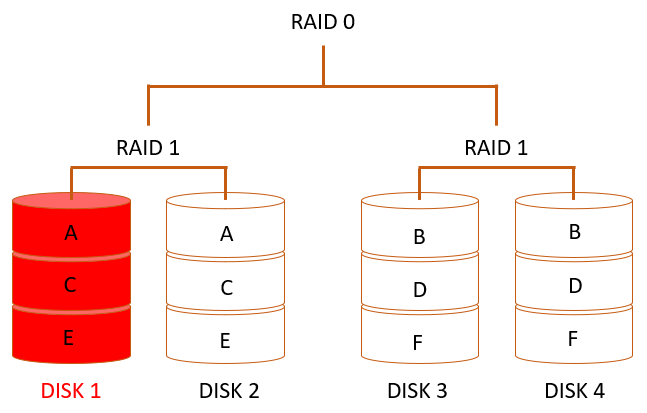
Даже если из строя выйдет ещё один диск – диск 3 (рис.3), характеристики RAID-массива с учётом вышеописанных предположений не изменятся.
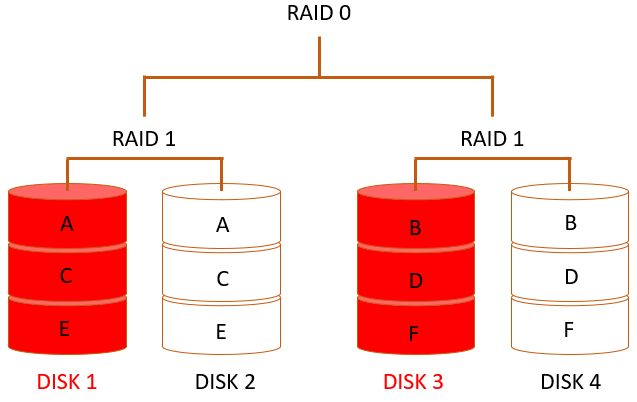
Т.е. выход двух дисков из четырёх не изменил функциональность дисковой системы – она по-прежнему обеспечивает хранение данных. Но отказоустойчивость уже минимально возможная (избыточности нет) – выход из строя любого из оставшихся дисков приведёт к отказу RAID-массива. Третий диск, вышедший из строя, приведёт к нарушению работы системы.
Но такой же печальный результат мы можем получить и при выходе из строя всего лишь двух дисков (рис.4).
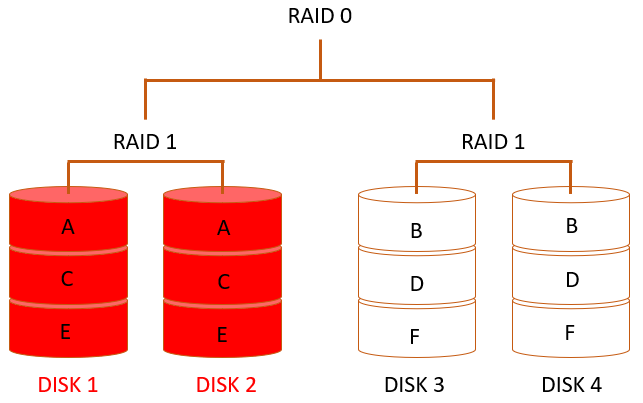
Таким образом, в первом сценарии (рис.2, 3) выход из строя диска 1 и диска 3 не является инцидентами. А выход из строя диска 2 является. А во втором сценарии (рис.4) выход из строя диска 1 не является инцидентом, а диска 3 – является. Получается, что одно и то же событие в реальном мире (в нашем примере выход из строя диска) может быть инцидентом, а может и не быть. Что, с одной стороны, логично, ведь влияние этого происшествия на услугу в разных ситуациях будет разным. С другой стороны, нам нужна определённость для принятия решения о том, как должно обрабатываться такое происшествие. Следовательно, в качестве события, на основе которого мы будем принимать решение, должно быть что-то иное, а не выход из строя диска. Например, выход из строя одного из зеркал (RAID 1). Или изменение каких-то характеристик массива. В крайнем случаем мы можем описать (перечислить) все допустимые и недопустимые ситуации, чтобы на практике однозначно принимать решение о том, отрабатывать ли нам ситуацию как инцидент или как-то иначе.
Получается простая, как мне кажется, конструкция. То, как мы определяем норму, определяет, что для нас будет инцидентами (и, соответственно, потребует скорейшего устранения), а что эту самую норму не нарушает, и может обрабатываться в плановом порядке.
Если мы исходим из того, что какой-то компонент (диск в дисковом массиве, сервер в кластере, батарея в системе электропитания) должен работать всегда, то выход их строя этого компонента является инцидентом. Если мы исходим их того, что элемент может выйти из строя, и это часть нормы, то это не инцидент. Последнее возможно только, если мы позаботились о дублировании.
Таким образом, дело не только в определении термина, но и в том, как мы планируем организовать работу, обеспечивающую предоставление услуги с согласованными характеристиками.
Дополнительно можно заметить, что с точки зрения описания модели услуги мы можем не рассматривать абсолютно все компоненты, из которых состоит услуга, как конфигурационные единицы. Конфигурационная единица определяется как
«компонент, которым необходимо управлять для предоставления ИТ-услуги» («Any component that needs to be managed in order to deliver an IT service» [Service configuration management: ITIL 4 Practice Guide, 2.2.1])
Если вам кажется, что всё это как-то слишком сложно, то вот ещё 😊
Мы можем определить регистрацию инцидентов в случае, когда «кажется, что что-то идёт не так». Это, кстати, почти дословная цитата из уже упоминавшегося руководства ITIL 4 по управлению инцидентами. Нужно только чётко определить, кто и при каких условиях может регистрировать инцидент на основании этого «кажется». Более того, в предлагаемом в «Incident Management ITIL 4 Practice Guide» примере алгоритма принятия решения о том, с инцидентом ли мы имеем дело, есть и такая развилка: «Пользователь несчастлив?» («Is user unhappy?») 😉
Поэтому нет смысла спорить по поводу является ли какое-то конкретное происшествие в реальном мире инцидентом, или нет.
Выводы
Если разобранная ситуация кажется слишком банальной, то, возможно, небесполезным будет задуматься над причинами, которые затрудняют разбор подобных вопросов.
Мне кажется, что одной из таких причин является то, что некоторые пытаюсь делать выводы, руководствуюсь лишь формальной логикой. С одной стороны, логика – полезная штука. С другой стороны, ограничивая себя только текстом какой-либо (пусть и очень умной книги), воспринимая его буквально, и пытаясь применять в лоб везде, где есть совпадение известных из текста слов, мы можем попадать в странные ситуации. Например, некоторые считают, что картина, в которой один инцидент вызван другим инцидентом, невозможна. «Ведь в определении термина «проблема» сказано, что «проблема – это [потенциальная] причина одного и более инцидентов. А, следовательно, причинно-следственной связи между инцидентами быть не может».
Вместо подобного прямолинейного подхода стоит разобраться комплексно (для этого небесполезно прочесть умную книгу целиком). В т.ч. попытаться ответить себе на вопрос, зачем мы, выстраивая систему управления в реальной жизни, будем использовать то или иное понятие. Наша задача, опираясь на знание определений, не просто разложить по кучкам сущности, с которыми мы сталкиваемся (или можем столкнуться) в окружающем нас мире: «это – инциденты; это – проблемы; это – запросы на обслуживание…». Нужно дополнить знание определений тех или иных понятий пониманием того, зачем нужны эти понятия. Только таким образом мы сможем применить теорию ITSM на практике, определить охват практик и границы соответствующих объектов управления будь то инциденты, запросы на обслуживание, проблемы, изменения и пр.
Это сложнее, чем жонглирование определениями. Для этого нужно разобраться более глубоко и более полно. Но только так мы можем получить от ITSM практическую пользу. В противном случае мы будем принимать управленческие решения, находясь в загадочном мире, где «проблема – это сложный инцидент», или «стандартные изменения – это запросы на обслуживание», или… (список можете продолжить).

А что на счет такого примера — на диске с базой данных критического сервиса осталось менее 10% места, через 1-3 часа сервис остановится если не увеличить место. Это инцидент или нет? 🙂