Хочу написать про еще одну технику управления рисками, незаслуженно забытую в книгах ITIL V3 2007 года, но восстановленную ("по чертежам" ITIL V2) в прошлогоднем обновлении.
Я говорю о расширенном жизненном цикле инцидента (the Expanded Incident Lifecycle). Это раздел в описании процесса управления доступностью (Availability Management), где предлагается разделять каждый инцидент (незапланированный перерыв в нормальном предоставлении ИТ-услуг) на обязательные последовательные этапы.
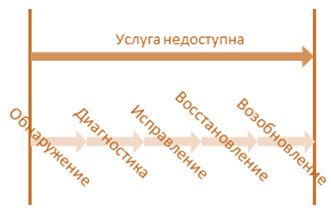
- Момент возникновения инцидента, то есть, момент, когда пользователь ощутил снижение качества ИТ-услуги
- Обнаружение, то есть промежуток времени от возникновения до момента получения поставщиком ИТ-услуг информации об инциденте
- Диагностика, то есть время на поиск причины инцидента
- Исправление, то есть время на исправление сбоя или замену сбоящего ИТ-компонента
- Восстановление, то есть время на завершение ремонтных работ в инфраструктуре
- Возобновление, то есть время от момента "восстановления" до начала нормальной работы пользователя.
- Момент закрытия инцидента, то есть момент завершения возобновления.
Позволю себе немного арифметики:
Момент закрытия – Момент возникновения =
Обнаружение + Диагностика + Ремонт + Восстановление + Возобновление
Общая идея такая: процесс управления доступностью может анализировать время, затрачиваемое на каждый из этапов, и пытаться оптимизировать соответствующую этому этапу деятельность:
Например, услуга была недоступна для пользователей 1 час, но при этом, работы по исправлению ошибки продолжались 5 минут. Куда делись остальные 55?
При первом прочтении меня больше всего заинтересовал в ITIL V3 пассаж про диагностику. Примерно такой:
Для некоторых сбоев, диагностика будет увеличивать общую длительность простоя. Однако, не-получение нужной диагностической создаёт риск повторных сбоев.
Мне показалось, что здесь есть ещё одна отсылка к извечному противостоянию менеджеров инцидентов и менеджеров проблем.
Диагностика "сбой услуги" — "сбой компонента" должна осуществляться, чтобы определить, что именно следует чинить\менять для восстановления нормальной работы пользователей. Более глубокая диагностика, направленная на постоянное устранение причин сбоев уже должна осуществляться в управлении проблемами. Так на уровне определения процессов разделяется управление инцидентами и проблемами.
Но тут ITIL предлагает утопическую идею: а пусть в ходе диагностики, менеджер инцидентов "поднимет голову" и решит, стоит ли уже в ходе решения конкретного инцидента "один раз день потерять, но разобраться с такими инцидентами раз и навсегда".
Мне кажется что идея очень здравая, её имеет смысл включать в регламенты процесса, с тем, чтобы менеджер не боялся своего главного KPI: среднего срока устранения инцидентов.

Господа, мы ведь не зря составляем какие-то SLA и согласовываем их с потребителями-пользователями. По хорошему в это SLA мы должны в том числе закладываться и временем на диагностику. Почему мы должны решать всё как можно быстрее? Не установив сути иницдента нельзя его решить. Не всё решается перезагрузкой сервера/компьютера.
Надо различать глобальную цель: решать как можно быстрее для чего необходимо: совершенствовать диагностику, составлять типовые решения, разрабатывать технологические карты решений и т.д.
А решение отдельного инцидента, не должно выполдняться под этим лозунгом.
Поспешишь, Людей посмешишь, говорит русский эпос.