Поиски методов и инструментов, реализующих идею системного подхода в ИТ, привели меня на поле системной динамики. Признаюсь, для меня эта дисциплина стала, наверное, самым волнующим открытием за все время изучения менеджмента. Среди базовых методов системной динамики есть causal loop diagram – диаграмма, которая позволяет отражать влияние разных переменных, характеризующих работу системы, друг на друга для объяснения поведения системы, часто контринтуитивного.
Простой пример CLD:
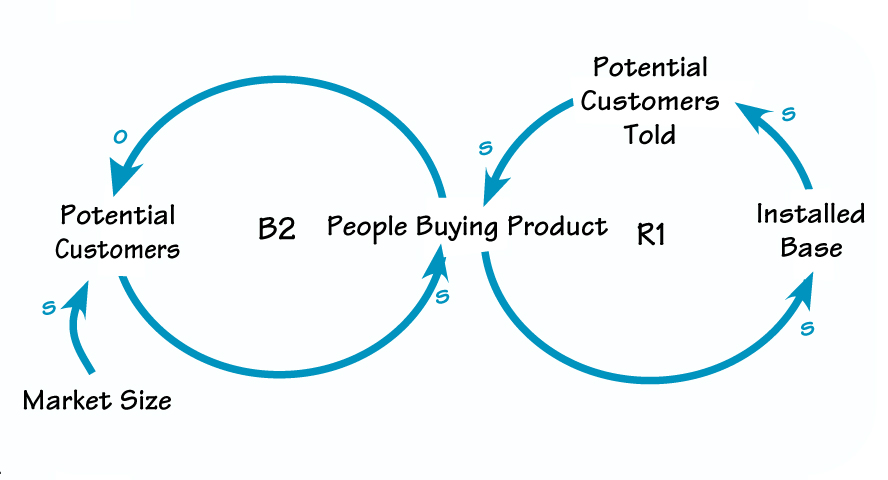
Источник: The Systems Thinker
На диаграмме есть:
- Переменные (Market Size, Potential Customers, People Buying Product и так далее).
- Связи: S (same) – одна переменная прямо пропорциональна второй (например, чем больше людей, купивших продукт, тем больше клиентская база); O (opposite) – одна переменная обратно пропорциональна второй (например, чем больше людей купивших продукт, тем меньше остается потенциальных клиентов).
- Символами R и B как правило обозначаются циклы или петли обратной связи: R (reinforcing loop) – усиливающие циклы; B (balancing loop) – балансирующие циклы.
Так случилось, что параллельно с открытием для себя causal loop diagram, я читал DevOps Handbook, в котором описывается так называемый The Core Chronic Conflict (CCC). Авторы книги определяют ССС следующим образом:
«Нисходящая спираль, обусловленная конфликтом интересов между разработкой и эксплуатацией, которая приводит к замедлению времени вывода решений в продуктив, снижении качества услуг, увеличению количества и продолжительности сбоев, накапливанию проблем и перманентному тушению пожаров».
Слова нисходящая спираль и дальнейшее описание "разложения" ИТ в трех актах навели меня на мысль, что за проблемой, описываемой в книге, непременно скрывается парочка циклов. И я решил немного порисовать.
Построение Causal Loop Diagram
Природа описанных выше явлений обусловлена, как мы давно знаем, двумя конфликтующими целями ИТ:
- Мы должны поддерживать развитие бизнеса и быстро проводить изменения.
- Мы должны предоставлять услуги высокого качества (стабильные, надежные, безопасные и так далее).
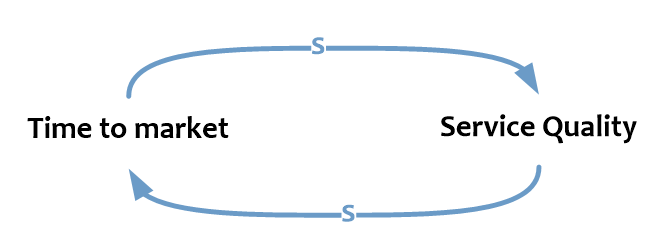
Чем быстрее мы хотим проводить изменения (меньше Time to market), тем на большие риски мы идем с точки зрения качества услуг (меньше Service Quality). Чем большую защиту продуктивной среды мы хотим обеспечить (больше Service Quality), тем больше времени у нас уйдет на реализацию изменений (больше Time to market).
Конечно, Time to market и Service Quality влияют друг на друга не напрямую, а через связанные переменные. Time to Market (или, согласно DevOps Handbook, Lead Time) складывается из Process Time (времени работы над изменением) и Queue Time (времени ожидания изменения в очереди). В свою очередь качество услуг (Service Quality) связано обратно пропорционально с рисками проведения изменений (Change Risk).
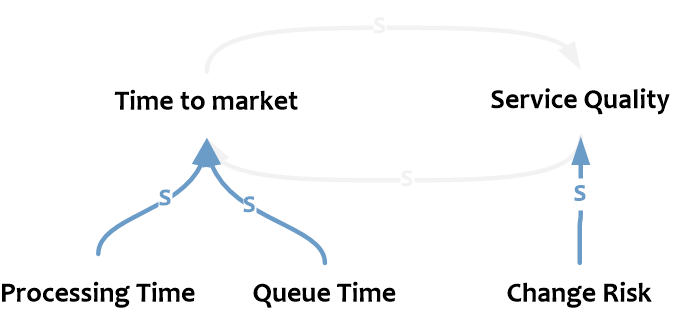 Одни из ключевых переменных, за счет которых мы обеспечиваем баланс Agility vs Stability – это:
Одни из ключевых переменных, за счет которых мы обеспечиваем баланс Agility vs Stability – это:
- Release rate – частота внедрений.
- Release size – средний размер внедрения (строчки кода, количество релиз юнитов в одном релизе и так далее).
Сделаю оговорку, что в данном тексте я явно не разделяю понятия Change, Release и Deploy, так как в ITSM- и DevOps-литературе они раскрываются немного по-разному, а уходить в сторону описания различий совершенно неуместно. Здесь и далее под Release я понимаю любое единичное внедрение в продуктивную среду.
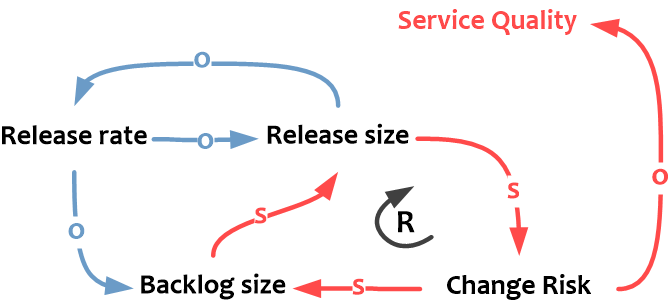
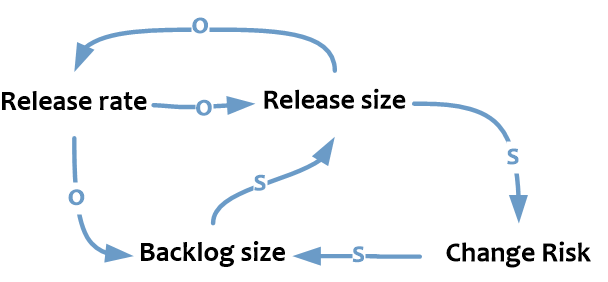 При этом, чем чаще внедряемся (выше Release rate), тем меньшими порциями можем это делать (меньше Release size), и наоборот.
При этом, чем чаще внедряемся (выше Release rate), тем меньшими порциями можем это делать (меньше Release size), и наоборот.
Увеличение размера релиза в свою очередь приводит к повышенным рискам (сложнее планировать и контролировать изменение, учесть все связи и так далее).
Частые внедрения (выше Release rate) помогают сокращать размер очереди (меньше Backlog Size). При этом длинная очередь изменений, весьма вероятно, будет подталкивать нас "укрупнять" внедрения (повышать Release Size), что опять увеличивает риски (Change Risk).
В свою очередь, чем выше риски, тем большее число внедрений заканчиваются неуспешно, и, следовательно, потребуются дополнительные изменения для устранения последствий или корректировки результатов проведенных неудачно или с ошибками (что означает рост Backlog size).
И это довольно важная история: описанная зависимость является усиливающей петлей обратной связи (reinforcing loop). Без целенаправленных воздействий на систему рост любой из переменных цикла будет приводить к ее дальнейшему росту.
 С другой стороны, рост Backlog Size приведет к увелечению времени ожидания изменений в очереди (Queue Time) и, следовательно, росту Time to Market.
С другой стороны, рост Backlog Size приведет к увелечению времени ожидания изменений в очереди (Queue Time) и, следовательно, росту Time to Market.
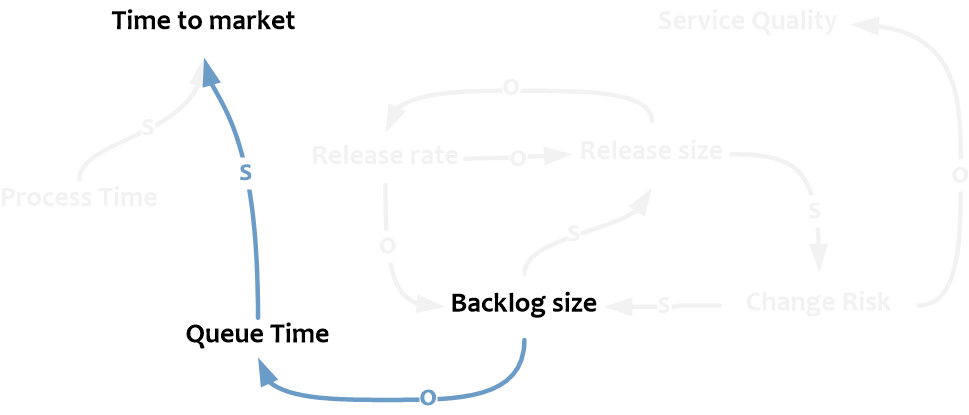
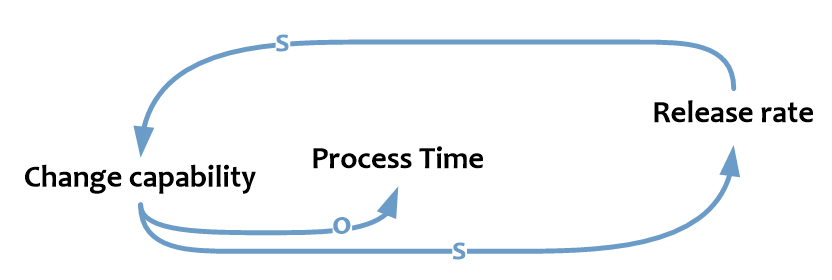
Помимо Queue Time на Time to market влияет Process Time – время работы над изменением.
Process Time во многом определяется нашей способностью проводить изменения (Change capability), которая определяется:
- ресурсной базой, доступной для проведения изменений;
- уровнем компетенций ИТ-специалистов;
- наличием знаний и опыта, обеспечением свободного обмена информацией.
Один из важных посылов в DevOps: чем выше Release Rate, чем чаще нам предоставляется возможность учиться на собственных ошибках, отрабатывать взаимодействие, усваивать уроки. Таким образом, можно наблюдать еще одну усиливающую петлю обратной связи, на сей раз положительную.
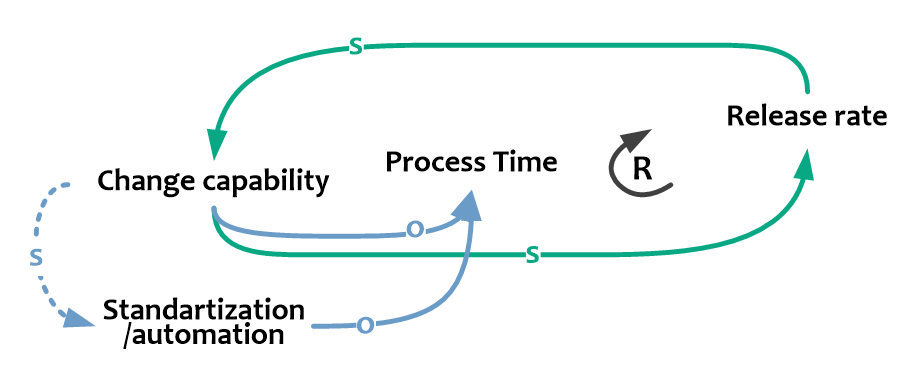
Чем чаще мы внедряемся (выше Change rate), тем быстрее накапливаем знания и опыт (выше Change capability), что в свою очередь позволяет нам ритмичнее работать (выше Change Rate), и так далее.
В свою очередь накопленный опыт и возросшие способности позволяют стандартизировать и автоматизировать проведение типовых изменений (чем, впрочем, мы не обязательно воспользуемся, поэтому – пунктир), что опять же сокращает среднее время внедрений (выше Standardization/automation, ниже Process Time).
Наконец, Process Time также зависит от того, насколько гладко проводятся изменения – как много изменений внедряется с первого раза без возвратов на предыдущие этапы или доработку (First-Time Implementation Rate).
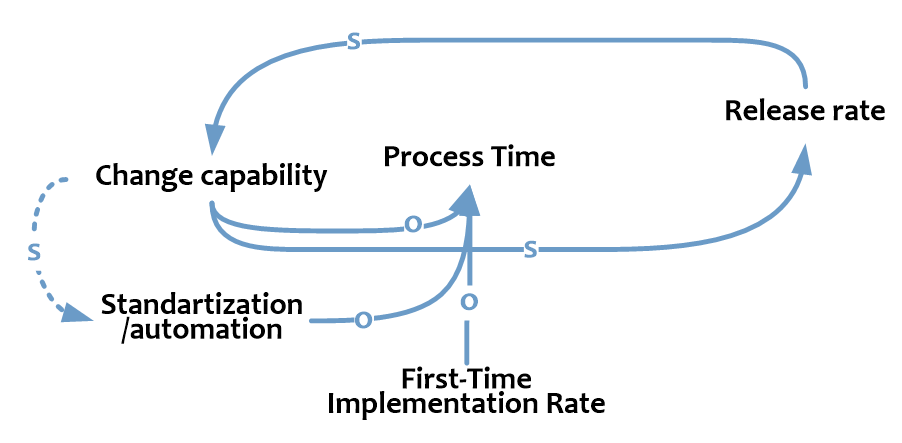 Шансы внедриться с первого раза тем выше, чем выше качество и точность планирования, оценки и тестирования (Change Control Level). Высокий Change Control Level сокращает Change Risk, но в то же время отнимает время (выше Process Time). И это – главная развилка в процессе управлении изменениями.
Шансы внедриться с первого раза тем выше, чем выше качество и точность планирования, оценки и тестирования (Change Control Level). Высокий Change Control Level сокращает Change Risk, но в то же время отнимает время (выше Process Time). И это – главная развилка в процессе управлении изменениями.
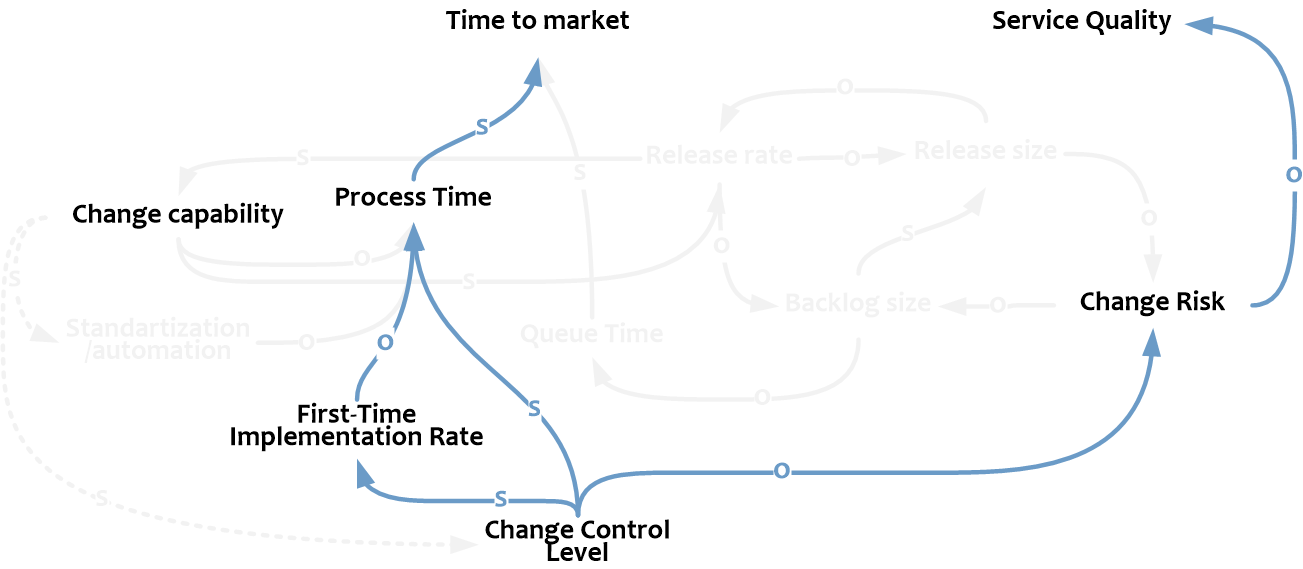 Диаграмма целиком.
Диаграмма целиком.
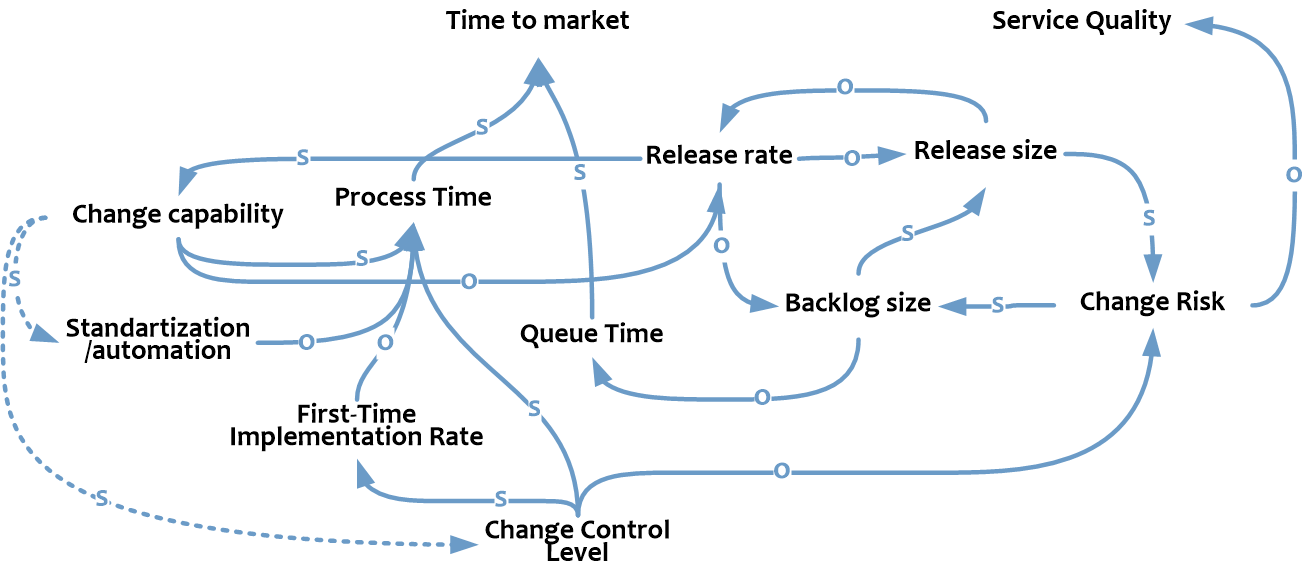 Безусловно, это не исчерпывающий набор факторов влияющих на Time to market и Service Quality, но диаграмма включает большинство ключевых переменных, связанных с DevOps, и на ее основе, кажется, уже можно проиллюстрировать важные явления системы управления ИТ. Попробуем.
Безусловно, это не исчерпывающий набор факторов влияющих на Time to market и Service Quality, но диаграмма включает большинство ключевых переменных, связанных с DevOps, и на ее основе, кажется, уже можно проиллюстрировать важные явления системы управления ИТ. Попробуем.
Как ИТ терпят поражение
В DevOps Handbook нисходящая спираль описана в трех актах.
Первый акт связан с планомерным ростом комплексности инфраструктуры, которая к тому же плохо задокументирована и в силу огромного количества нерешенных проблем и обходных решений чрезвычайно хрупка.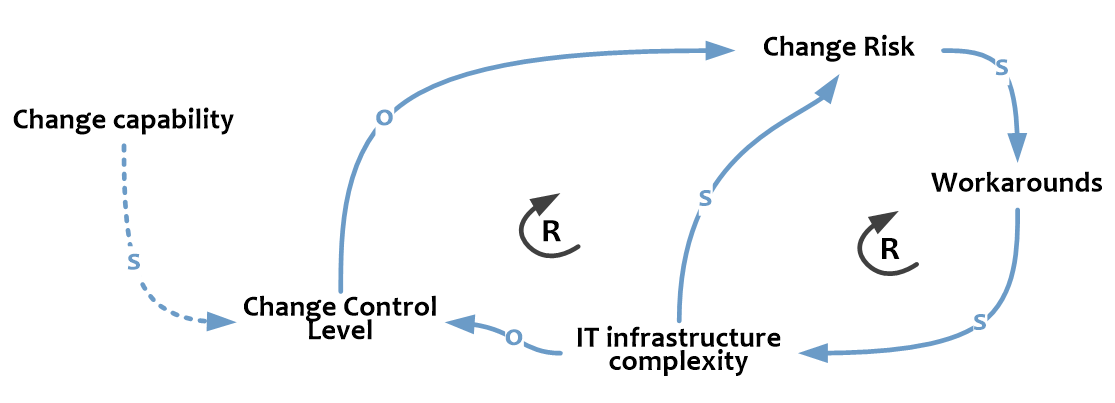
Как это выглядит на CLD? Чем больше нерешенных проблем и обходных решений (Workarounds), тем выше комплексность инфраструктуры (IT Infrastructure Complexity). Это с одной стороны повышает хрупкость систем, которые с большей «охотой» падают даже от незначительных изменений (выше Change Risk), а с другой стороны усложняет планирование (снижает Change Control Level) – никто уже давно толком не знает, как это работает. К тому же ни у кого нет времени на документирование, а значит у нас все меньше и меньше знаний, на которые можно опираться при контроле изменений. Мы все больше зависим от конкретных людей, на них, спасителей, и надеемся. Повышенные риски приводят к новым провалам и новым обходным решениям, что образует сразу две усиливающие петли обратной связи.
Второй акт начинается, когда BRM, product- или service-менеджер для компенсации ранее проваленных изменений обещает все исправить, инициируя пачку новых изменений, которые, конечно же, нужно реализовать в сжатые сроки. Естественно, никто в ИТ к такому повороту не готов. В результате, инициируются экстренные изменения (проект), все причастные в поте лица срезают углы, пренебрегая планированием, оценкой и тестированием. Это вновь приводит к провалам, новым проблемам и обходным решениям. Времени на то, чтобы привести все в порядок, конечно, не хватает. Его едва хватает на сон.
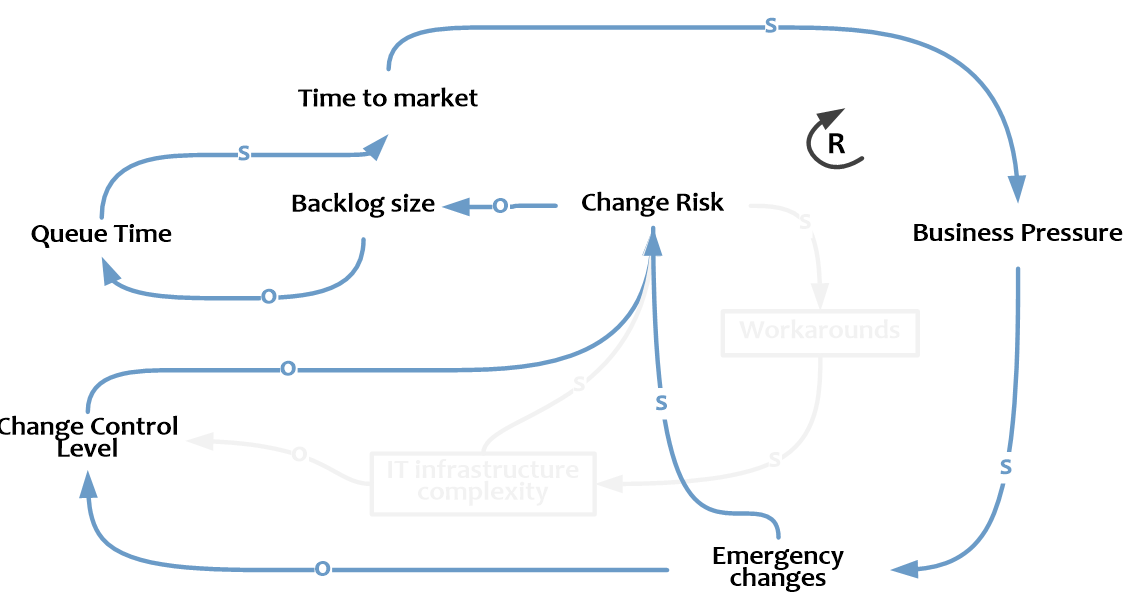 Как это отразить на CLD? Высокий Time to market со временем приводит к росту давления со стороны бизнеса, подталкивая нас к проведению срочных изменений (Emergency changes) и срезанию углов (ниже Change Control Level). Оба фактора повышают долю неуспешных изменений и, следовательно, дальнейший рост бэклога, что только увеличивает Time to market и рост давления бизнеса на ИТ.
Как это отразить на CLD? Высокий Time to market со временем приводит к росту давления со стороны бизнеса, подталкивая нас к проведению срочных изменений (Emergency changes) и срезанию углов (ниже Change Control Level). Оба фактора повышают долю неуспешных изменений и, следовательно, дальнейший рост бэклога, что только увеличивает Time to market и рост давления бизнеса на ИТ.
Это конечно упрощенная иллюстрация. В действительности на этом этапе также активна петля обратной связи из предыдущего акта и активируются большинство оставшихся элементов causal loop diagram, запуская каскадный эффект.
Наконец, третий акт характеризуется крайним замедлением работы, всеобщим страхом и отчаянием: все заняты, но ничего не могут сделать вовремя, постоянные сбои приводят к тому, что люди боятся брать на себя ответственность, любое даже незначительное изменение требует долгих коммуникаций и авторизаций.
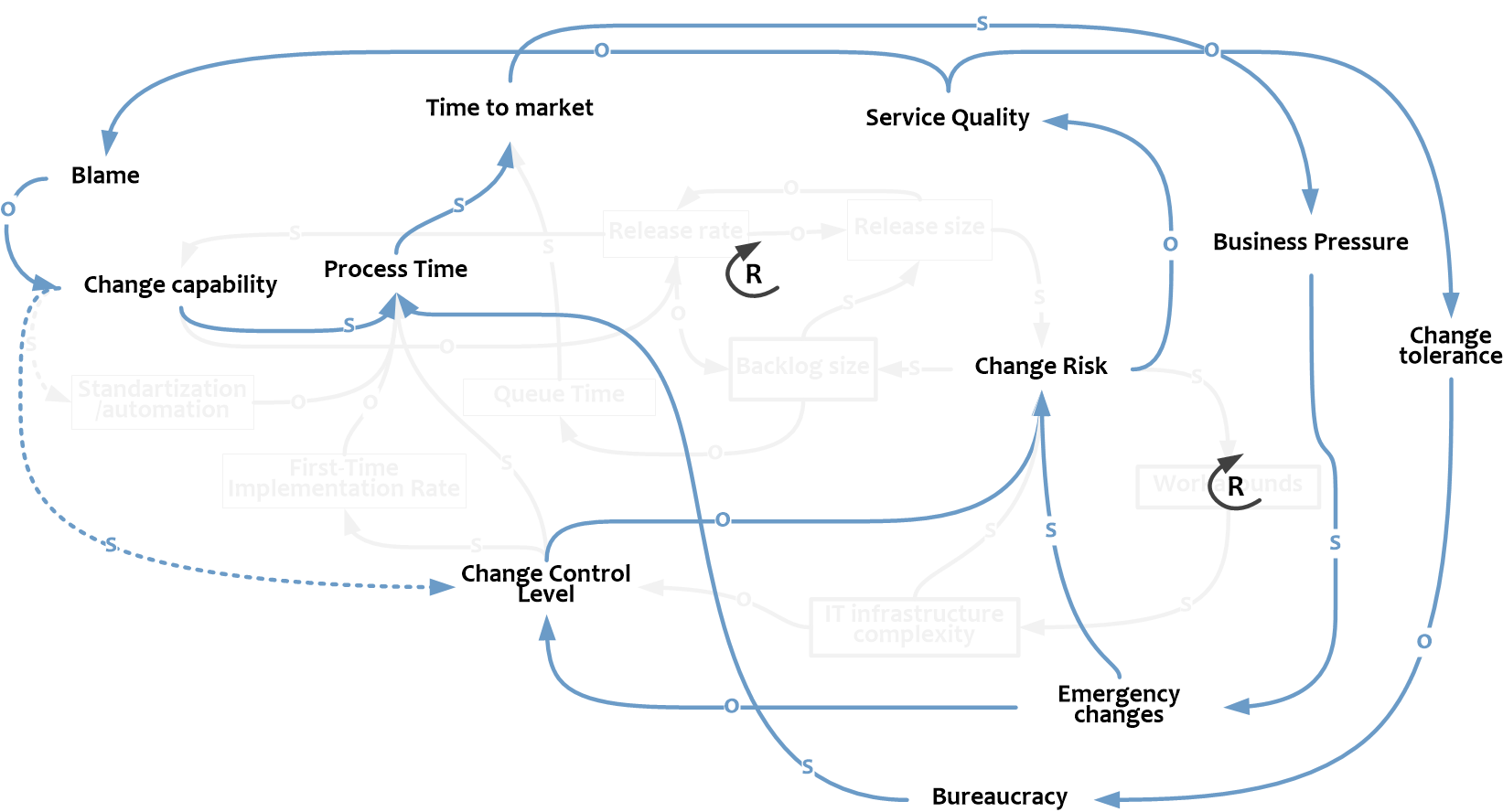 Отразим это на CLD. Высокие риски и, как следствие, низкое качество услуг приводят к тому, что люди и организация в целом становятся все менее и менее терпимы к изменениям, усложняются коммуникации и в качестве защитного механизма в системе появляется большое количество избыточных согласований и авторизаций (рост Bureaucracy). Время проведения изменений продолжает расти, усиливая давление со стороны бизнеса и далее по цепочке все явления, описанные во втором акте.
Отразим это на CLD. Высокие риски и, как следствие, низкое качество услуг приводят к тому, что люди и организация в целом становятся все менее и менее терпимы к изменениям, усложняются коммуникации и в качестве защитного механизма в системе появляется большое количество избыточных согласований и авторизаций (рост Bureaucracy). Время проведения изменений продолжает расти, усиливая давление со стороны бизнеса и далее по цепочке все явления, описанные во втором акте.
С другой стороны постоянные провалы приводят к постоянным поискам и наказанию "виновных". Люди занимают оборонительную позицию и практически прекращают обмен знаниями, уроки из ошибок не извлекаются и не усваиваются, что приводит к новым и новым ошибкам и, в конечном счете, неспособности ИТ ни проводить изменения, ни обеспечивать надежную работу того, что навнедряли ранее. Занавес.
Комментарии
Важное открытие, которое я сделал в процессе выполнения этого упражнения – роль циклов. Если переходить от описания проблем к возможным вариантам их решения, можно обнаружить, что воздействий на отдельные переменные будет недостаточно, чтобы вернуть систему в равновесие – мы должны учитывать циклы, в которых эти переменные состоят, и думать в терминах «оздоровления» цикла. Или "запускать" новый цикл – с балансирующей петлей обратной связи. Но об этом не сегодня.
Есть и очевидные сложности. Во-первых, с расширением (увеличением количества переменных) диаграмма практически перестает быть читаемой. Поэтому важно всегда держать в фокусе конкретный вопрос, проблему или явление, которые требуется проанализировать, и строить анализ вокруг, отсекая все лишнее. Что не просто, так как в ходе анализа непременно открываются все новые и новые факторы. На каком основании их включать в диаграмму, а в каком случае пренебрегать? Как найти баланс между точностью, детализацией и информативностью? Для меня это пока открытые вопросы.
Во-вторых, диаграмма предлагает определенную логику связей между переменными, но всегда ли она справедлива? Один из споров, который возник на внутреннем обсуждении диараммы у нас в Cleverics: всегда ли большой Backlog будет приводить к увеличению среднего размера внедрений. Может быть, в конкретном случае эта связь на отработает. Может быть, таких спорных связей, которые вовсе не отражают общий случай больше, чем мне кажется. Я не знаю, поэтому буду рад комментариям тех, кто читает эти строки.
Однако ни первая, ни вторая сложность, кажется, не являются камнем преткновения в использовании CLD как способа объяснения явлений, наблюдаемых в системе управления – себе или слушателям/коллегам/заказчикам. А с того момента, как достигнуто понимание и согласие по структуре конкретной диаграммы, открываются новые возможности – по анализу того, что выводит систему из равновесия, и по планированию вмешательства так, чтобы изменить состояние всей системы, а не отдельных ее элементов (за счет того, что все ключевые взаимосвязи на виду). И эта визуализация идеи системного мышления, о которой так много пишут в книжках про менеджмент, меня, конечно, очень вдохновляет.


Павел, у меня подозрение, что на схеме не совсем корректно помечены связи Release Size-Change Risk и Change Risk-Backlog Size, они же пропорциональные, а не оппозитные (на схеме помеыены, как "о"). Вот ниже ссылка на текст ваш.