Многие компании существенно зависят от очень важного компонента – мониторинга инфраструктуры и приложений.
Это ответственная область, к которой нужно относиться очень серьёзно и понимать, насколько важно для пользователя сразу знать, связана ли обнаруженная проблема с их собственными системами. Именно поэтому одна из компаний, являющихся поставщиком мониторинговых решений, публикует внутренние системные метрики “здоровья” системы измерения на общедоступном ресурсе.
Они руководствуются принципом «открытости по умолчанию», где прозрачность – основа работы. Это очень значимо для технически подкованных пользователей, которые ценят высокий уровень детализации данных о том, как работают их службы.
Но системные метрики, которые показывают вас с хорошей стороны, не всегда являются теми метриками, которые важны для пользователей. Что же выбрать?
Укрепление доверия vs отличный внешний вид
Поначалу идея публиковать метрики, которые в противном случае были бы скрыты от пользователей, казалась пугающей и вызывала некоторый внутренний конфликт в команде. Что, если что-то пойдет не так? Не будет ли неловко, если возникнут проблемы, и каждый сможет наблюдать, как мы их исправляем? Конечно, «да», но было принято решение рассматривать это как некую функцию, а не ошибку.
Аргумент сводился к тому, что лучше для пользователей: хорошо выглядеть на бумаге или дать им данные, которые позволят принимать правильные решения?
Хотя это и не всегда удобно для поставщика, публикация большого количества данных поможет пользователям самостоятельно диагностировать проблемы – зачастую перед отправкой запроса на поддержку. Вместо состояния разочарования и неопределенности, пользователи могут оперативно проверить свою страницу мониторинга, чтобы понять, соответствует ли текущая картина происходящего тому, что должно быть.
Быстрое предоставление информации – залог доверительных отношений.
Помимо прочего, публикация метрик повысила и качество работы команды. Когда всё открыто, намного сложнее игнорировать собственный технический долг. Дополнительный уровень контроля означает, что больше нельзя игнорировать проблемы и надеяться, что пользователи не заметят их, поэтому команда мотивирована на создание более устойчивых систем.
Информация на странице мониторинга
Достаточно легко ошеломить пользователей кучей графиков, которые зачастую трудны для понимания, особенно, без правильной системы отсчета. Поэтому любые показанные метрики должны быть понятны и ограничены теми частями сервиса, которые действительно волнуют пользователей.
В данном случае, одним из наиболее важных компонентов сервиса является состояние конвейера, работы интеграционных интерфейсов, ключевых портов и каналов, доступности AWS и другое. Пользователи полагаются на поставщика в части обработки и хранения своих данных мониторинга, поэтому возможность проверить статус этой услуги очень важна. В связи с этим, на странице мониторинга публикуется внутренняя метрика состояния для каждого ключевого протокола, который поддерживается. Пользователи имеют доступ к просмотру в реальном времени тех же показателей, что и поставщик решения, и получают оповещения в случае непредвиденных событий.
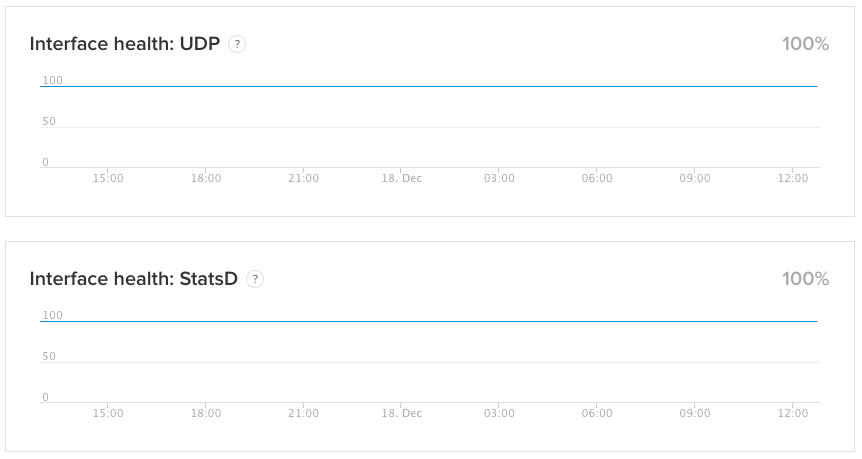
Метрики работоспособности интерфейса
Метрики, относящиеся к мониторингу состояния конвейера составляют большую часть общедоступных публикуемых метрик, поскольку позволяют разбивать измерения по точкам подключения и протоколам. Для отправки данных пользователи могут выбирать из большого числа разнообразных протоколов, и кто-то, отправляющий данные через HTTP API, не волнуется о состоянии конечных точек UDP. Иногда мониторинг осуществляется с различных точек, т.к. пользователи могут использовать те или иные ресурсы и протоколы из различных локаций. Поэтому отображение состояния здоровья интерфейсов в виде совокупности (например, среднего значения) может привести к путанице.
Статистика безотказной работы
Поставщик услуги мониторинга также делится собственной статистикой безотказной работы их веб-сайта и временем отклика на обслуживаемые запросы по объектам мониторинга. Это позволяет пользователю, в случае медленного времени отклика у них, проверить, является ли это распространенной проблемой, не является ли сообщение о сбое ложным.
Какие показатели важны для вашего клиента?
В конечном счете, необходимо поставить себя на место ваших пользователей. Откройте свою страницу состояния и спросите: “Что бы я хотел увидеть здесь, если бы использовал наш сервис и начал испытывать проблемы?”
Ключевая цель – предоставить пользователям доступ к общей картине состояния вашего сервиса.
Даже если у вас есть очень много данных по вашим сервисам, вы все равно точно знаете, какие из метрик действительно важны. Обычно это касается систем, которые в первую очередь влияют на ваших пользователей. Вот несколько правил, которые помогут выбрать метрику:
- Оказывает ли метрика непосредственное влияние на работу пользователей?
- Если пользователь увидит эту метрику, поможет ли она ему понять, касается ли проблема только его или всех?
- Если я опубликую эту метрику, могу ли я дать ей чёткое, простое название и объяснение?
Публикуйте и “внутренние” и “внешние” метрики, выстраивайте доверие
Оригинал When it comes to system metrics, skip vanity and promote transparency, автор Шеннон Уинтер (Shannon Winter)

Какая-то путанная статья из сплошных противоречий. Метрики надо публиковать, но большое количество метрик может запутать пользователя и т.д. Такое впечатление, что автор не в курсе про SLA. Вроде декларируется правильный тезис – “Ключевая цель — предоставить пользователям доступ к общей картине состояния вашего сервиса.” , но метод реализации весьма странный. Общая картина состояния сервиса – это согласованный SLA, и действительно, очень хорошо, если вы можете предоставить заказчику возможность самостоятельно контролировать состояние SLA в онлайне. Это также очень полезно для подписания актов – пользователь может зайти в свой кабинет и проверить, были ли нарушения или нет. Но у автора предлагается вывалить на пользователя метрики и пусть он сам с ними разбирается. При этом, опять таки, без SLA не понятно что с этими метриками делать.