Текущей статьей мы заканчиваем серию статей про интересные уроки, которые можно вынести из аварийных ситуаций на основе реального опыта крупных международных компаний, которым они открыто поделились на своих сайтах (часть 1, часть 2, часть 3).
Одним из выводов компании Advenita стала важность SLO (Service level objective, цель уровня обслуживания). И если компания Reddit и относится к чему-то серьезно, так это к SLO: вот как сайт справлялся со своими ежедневными целями по уровню обслуживания в течение последних трех лет:
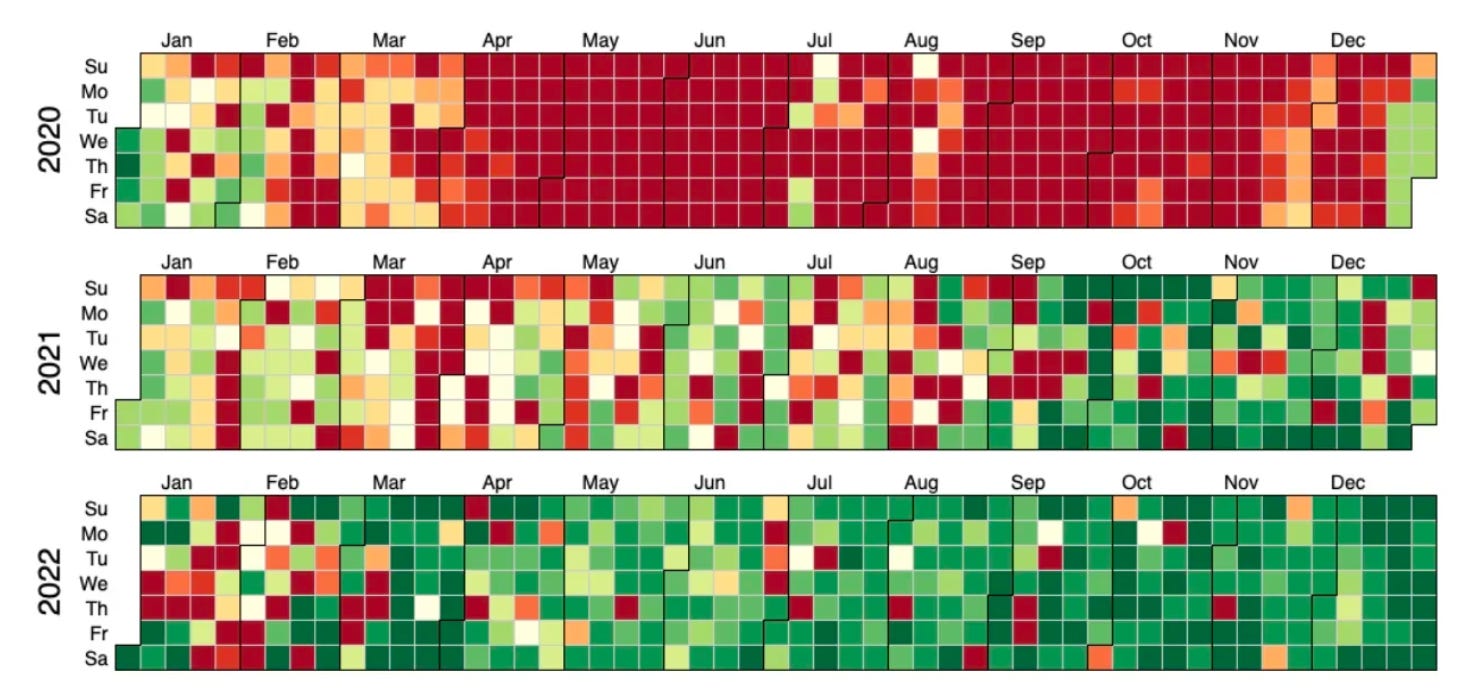
Налицо тенденция к улучшению работы сайта. Однако 14 марта Reddit не работал почти пять часов.
Reddit опубликовал результаты своего последующего анализа инцидента на сайте Reddit, и они не только познавательны, но и зачастую занимательны. Вот как начинается обзор:
«Это забавно в ироническом смысле. Мы, как команда, только что закончили внутреннее рассмотрение предыдущего обновления Kubernetes, которое прошло неудачно, но только в незначительной степени, и по полностью устраненной причине. Поэтому мы приступили к очередному обновлению того же кластера».
Reddit обновлял Kubernetes с версии 1.23 до 1.24. И вот что произошло:
«Этот цикл обновления был одним из основных направлений работы нашей команды в этом квартале, и один из самых важных кластеров компании, на котором работает Legacy-часть нашего стека (в сообществе его ласково называют «Старый Reddit»), был готов к обновлению до следующей версии. Инженер, выполнявший работы, запустил обновление сразу после 19:00 UTC, и в течение примерно двух минут все шло хорошо. А потом?
Хаос».

Когда Reddit не работает, на сайте появляются симпатичные изображения ошибок, подобные приведенному выше.
В процессе обновления произошел сбой, и команде Reddit необходимо было решить, как действовать дальше:
- Отлаживать ли проблему в реальном времени и пытаться ее устранить? Например, перезапустить сервисы, попробовав исправить ситуацию?
- Или восстановить кластер из резервной копии, причем восстановление сопровождалось бы многочасовым гарантированным простоем?
Инженерная команда начала с варианта №1 и перебросилась несколькими идеями по решению проблемы. Через час или два после того, как ни одна из идей не сработала, они решили начать многочасовой — и рискованный! — процесс восстановления из резервной копии.
После завершения восстановления резервной копии команда смогла выдохнуть и начать расследование того, что именно произошло. Расследование само по себе является мини-романом с загадками, и в конце концов команда нашла первопричину сбоя: изменение названия метки узла Kubernetes между релизами.
Возможно, изменение названия метки и было причиной, но это был симптом чего-то большего:
«Действительно, это косвенная причина. На самом деле причина носит более системный характер и является большой частью того, с чем мы сталкивались на протяжении многих лет: Несогласованность.
Практически каждый критически важный кластер Kubernetes в Reddit так или иначе нестандартен. Это естественное следствие органического роста, которое привело к большему количеству сбоев, чем мы можем легко отследить за прошедшее время. Важной задачей команды разработчиков является отказ от такого поведения и повышение однородности нашей среды, и мы действительно достигли этого».
Два самых важных урока, которые Гергелий Орош, автор данной статьи, вынес из обзора инцидентов, проведенного Reddit, заключаются в следующем:
— Восстановление на производстве — это сложно и страшно. Команда Reddit очень открыто и уязвимо рассказала о том, насколько напряженным было полное восстановление на производственном уровне, когда они не делали такого восстановления раньше. Можно имитировать сколько угодно восстановлений, но это не то же самое, что по-настоящему восстанавливать вcю продуктивную среду.
— Несогласованная инфраструктура может быть частым источником перебоев в работе. Reddit быстро развивался в течение многих лет. В их инфраструктуре появилось множество конфигураций, созданных по индивидуальному заказу, что вполне типично, когда команды работают автономно и быстро развивают свои куски инфраструктуры. В обзоре инцидента отражены как проблемы, связанные с таким внутренним наследием, так и план действий Reddit по обеспечению большей согласованности в инфраструктурном слое.
Постмортем отчет — необычайно увлекательное и познавательное чтение, и Гергелий настоятельно рекомендую ознакомиться с оригиналом.
Выводы
Спасибо Adevinta, GitHub и Reddit за то, что они опубликовали свои постмортемы для всеобщего анализа. Самые важные выводы, которые можно сделать из этих инцидентов, таковы:
— Хорошие SLI и SLO могут помочь быстрее обнаружить сбои. В случае с тщетными поисками первопричины сбоя в Adevinta: если бы команда обратила больше внимания на снижение задержек DNS в одном из кластеров, то, скорее всего, обнаружила бы проблемы в этой системе раньше.
— Процедуры аварийного восстановления рискованны, но их все равно нужно выполнять. Перебои в работе GitHub возникли после того, как команда инженеров провела учения по восстановлению после сбоев, готовясь к сценариям аварийного восстановления. Хотя простои в работе никогда не бывают приятными, риск их возникновения не должен останавливать вас от проведения таких упражнений, как аварийное переключение и восстановление после сбоя, или других сценариев аварийного восстановления. Конечно, следует действовать осторожно и иметь наготове план по откату, как это было сделано в GitHub.
— Восстановление полной резервной копии в производстве — это стресс, трудность и сложный выбор. В обзоре инцидента, опубликованном на Reddit, было очень честно рассказано о том, что команда не решалась сделать полный откат, даже когда возникли проблемы с обновлением Kubernetes, поскольку они никогда не делали подобного восстановления в производстве. И даже когда они завершили восстановление, им пришлось частично импровизировать.
— Быстрое развитие с автономными командами часто приводит к накоплению инфраструктурного долга. Reddit — это быстро развивающийся масштабный проект, где команды двигаются быстро, и, судя по всему, у них была автономия в принятии инфраструктурных решений. Широкий спектр конфигураций инфраструктуры привел к нескольким сбоям, и сейчас компания выплачивает этот «инфраструктурный долг». Это не значит, что автономные команды, работающие быстро, — это плохо, но это напоминание о том, что при таком подходе возникают компромиссы, которые могут повлиять на надежность, и в конечном итоге за них придется расплачиваться, часто силами выделенных команд.
