


Возможно, вы консультант или вновь назначенный ИТ-менеджер или просто очень любознательный сотрудник ИТ-департамента, который хочет разобраться, как работает управление ИТ в организации. Эти метрики помогут быстро составить впечатление от ИТ-департамента вашей организации и наметить следующие шаги.
Важные предостережения:
Вот эти метрики:
Анализ представленных показателей позволят быстро и на основе цифр составить портрет ИТ-департамента, подскажут путь дальнейшего анализа, посветят области, требующие внимания и приложения усилий. Разберем каждый из них.
Доля ИТ-затрат
Говорят, что технологии уже пронизывают каждую функцию организации и оказывают критическое влияние на все аспекты бизнеса. Но возможно конкретной организации – еще не до цифровой трансформации. Метрика наглядно показывает, насколько значимы ИТ для бизнеса и задает контекст для трактовки остальных показателей. Если возможно, хорошо бы взглянуть на метрику в первую очередь.
Почему важен
Позволяет оценить, насколько значимы ИТ для организации.
Как измерять
Если организация не выполняет аллокацию ИТ-затрат, то быстрое получение доступа к данным о фактических затратах может быть затруднительно. В этом случае, можно использовать бюджет.
Как использовать
Если первичные данные и модель аллокации ИТ-затрат позволяет, можно пойти в анализе чуть дальше и:

Уровень доступности
Доступность – первое, что приходит в голову, когда говорят о качестве ИТ-услуг. Уровень доступности – важнейший показатель потому, что отражает, как много бизнес теряет (точнее: может потерять) в связи со сбоями ИТ. Особенно важно, что ИТ-организация умеет измерять, оценивать и отчитываться о доступности ИТ-услуг.
Почему важен
Позволяет оценить бизнес-риски, связанные со сбоями ИТ.
Как измерять
Процент доступности – общепринятый показатель для измерения надежности ИТ-инфраструктуры, но он не годится для измерения доступности ИТ-услуг, предоставляемых ИТ-подразделением организации.
Первая сложность связана с обсуждением показателя. Доступность определена как 99,9%. Вроде неплохо. Но 0,1% в год равен почти 9 часам (при режиме эксплуатации 24x7). А в месяц – это почти 45 минут. А в неделю – чуть более 10 минут. Так какие 99,9% имел в виду бизнес-заказчик? А ИТ-менеджмент?
Однако значительно более существенен следующий нюанс: показатель довольно неточно отражает негативное влияние на бизнес. Что если все без малого 9 часов за год случились разом? Или услуга становилась недоступна потребителям по две минуты, но 15 раз за один день? Как это будет выражено в процентах?.. Поэтому, например, ITIL вводит такие показатели, как MTRS (Mean time to restore service), MTBF (Mean time between failures).
Вернемся в начало координат и зададимся вопросом: зачем мы вообще вводим показатели доступности? Почему бизнес предъявляет требования к доступности услуг? Почему сервис-провайдер должен обеспечивать высокую доступность и отчитываться по ее фактическим значениям? Ответ прост: бизнес несет потери вследствие простоев ИТ-услуг. Значит, идеальным для бизнеса показателем доступности, вероятно, была бы метрика «Потери вследствие простоев ИТ-услуг»?
Произвести расчет такой метрики возможно в основном для ИТ-услуг, непосредственно связанных с получением прибыли (продажи, кредитный конвейер и так далее). Таким образом, мы должны определить другие показатели, не забывая о том, что в совокупности они должны нести информацию о бизнес-влиянии (фактическом или потенциальном).
От чего зависят потери бизнеса вследствие простоев?
Альтернативной (или дополнительной) метрикой, отражающей тот же аспект, но с акцентом на периоде спокойной работы пользователей, может быть показатель «Минимальная (или средняя) продолжительность работы без нарушений».
Итого, в зависимости от ИТ-услуги возможно использовать один или несколько показателей:
Как использовать
Нередко для оценки деятельности ИТ-департамента показатели доступности услуг агрегируют для расчета общего KPI. Но чтобы получить представление о том, как ИТ справляется с управлением доступностью, нужно смотреть на них в “развернутом” виде – для этого будет достаточно взгляда га нескольких (до 5-6) ключевых ИТ-услуг, которые обеспечивают функционирование бизнеса, за 3-4 месяца. Особое внимание нужно уделить трендам и единичным провалам – они зададут направления для следующих шагов.

Incident rate
Incident rate также характеризует надежность ИТ. В отличие от уровня доступности он значительно менее требователен к средствам измерения и методике оценки (если есть ITSM-система, в которой регистрируются инциденты).
Кроме того, метрика косвенно показывает, насколько реактивно ИТ-подразделение и сколько ресурсов тратит на «тушение пожаров» вместо плановой работы.
Почему важен
Как измерять
Incident rate = количество запросов категории «Инцидент», поступивших за один месяц, в расчете на одного активного сотрудника организации – пользователя ИТ.
Лучше брать выборку за год в разбивке по месяцам, чтобы исключить сезонность. Из пользователей лучше исключить уволенных сотрудников и различные технические учетные записи.
Значение показателя может сравниваться с отраслевой статистикой. Она показывает, что значения этой метрики колеблются в довольно узком диапазоне – 0.4 - 2.3. Причем данный диапазон слабо зависит от размера организации и в основном определяется отраслью (например, в банках значения выше, чем в энергетике). Отраслевая специфика – это следствие влияния сложности применяемых информационных технологий и частоты их изменений.
Как использовать
У IR два направления для применения:

Своевременность обработки запросов
Метрика связана с ключевым обязательством ИТ-департамента перед бизнесом. В организации может не быть каталога услуг и SLA, но целевое время решения запросов пользователей задано и отслеживается везде. Решение запросов пользователей связано с коммуникацией, поэтому своевременное и результативное решение пользовательских запросов в существенной степени формирует общее восприятие ИТ.
Почему важен
Как измерять
На первый взгляд, своевременность обработки запросов измерить несложно: количество своевременно обработанных запросов нужно поделить на общее количество запросов, обработанных за некоторый период времени.
Однако за простотой этой формулы скрывается существенный недостаток – такое определение метрики своевременности не учитывает, на сколько был нарушен срок обработки запроса. Обычно пользователю не все равно, был ли его запрос просрочен на 5 минут или на неделю.
Отразить в метрике, насколько нарушен срок, можно следующим образом: количество своевременно обработанных запросов поделить на коэффициент Wi (вместо общего количества запросов). При этом Wi:
Тогда чем сильнее просрочен i-тый запрос, тем больше его вес Wi, снижающий значение метрики (поскольку ti > Ti).
Подробнее о показателе – в книге “Управление услугами на основе измерений”.
Как использовать
Оценить показатель для процесса в целом.
Оценить показатели TPI для групп поддержки – определить, какие группы поддержки являются узким местом процесса. Проанализировать возможные причины низкой своевременности решения.
Оценить «хвост» – количество нерешенных обращений в предыдущем периоде, перешедших в текущий.

Первый показатель, который мы предложили, – доля ИТ-затрат – касается роли ИТ в бизнесе организации. Последующие три – уровень доступности, Incident Rate, своевременность выполнения обращений – касаются эксплуатации. Следующие три показателя – про развитие.
Доля численности ИТ-персонала в развитии
Метрика доли ИТ-затрат показывает роль ИТ в бизнесе в целом. Метрика ‘Доля численности ИТ-персонала в развитии’ уточняет, насколько много ресурсов компания тратит на развитие информационных технологий. И соответственно, какое внимание ей следует уделять применению релевантных подходов и их развитию (agile, devops и так далее).
Почему важен
Показывает, насколько важна разработка для организации.
Как измерять
Если компания работает в режиме инсорсинга, расчет может быть проведен через численность персонала – как доля персонала в подразделениях развития в общей численности ИТ-персонала организации. Компании, делающих ставку на ИТ, и особенно в ИТ-зависимых областях (банки, ритейл) склонны возвращать разработчиков в инсорс, поэтому такой расчет для них может быть приемлем.
В ситуации активного использования аутсорса корректнее оценивать этот показатель через долю затрат на разработку от общих затрат ИТ-подразделения по ФОТ и услугам.
Как использовать
Если есть возможность, сравнить со значениями данного показателя с референсными компаниями (например, основными конкурентами или с компаниями-ориентирами). В компаниях с серьёзной внутренней разработкой данный показатель имеет значения 50-60% и выше.

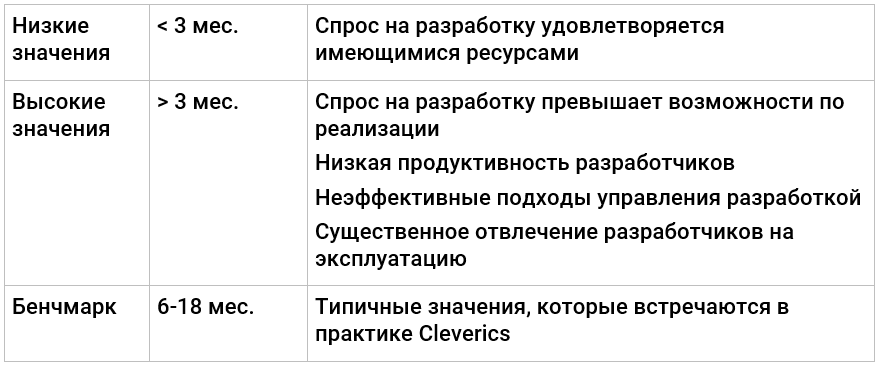
Размер бэклога (разработки)
Если компания прикладывает значительные усилия на развитие, то следующая метрика, на которую имеет смысл посмотреть, – это величина бэклога, очереди запросов, которые требуют реализации силами разработчиков.
Почему важен
Показывает баланс спроса на развитие ИТ и предложения.
Как измерять
Наилучший способ оценить очередь – посчитать суммарный объем трудозатрат на реализацию запросов на изменения во входной очереди. Такой показатель расскажет, сколько дней (недель, месяцев) займет реализация уже принятых запросов, если прием новых запросов прекратить (при неизменных ресурсах).
Если существенная доля запросов на изменения не имеет оценки трудозатрат, можно выполнить приблизительную оценку как произведение количества запросов на изменение в бэклоге на средние трудозатраты по одному запросу (на основании данных прошлых периодов).
Как использовать
Чем выше показатель, тем меньше ресурсное обеспечение разработки соответствует спросу внутренних заказчиков организации. Значения больше трех месяцев могут означать нехватку ресурсов и/или скорости реализации, которая определяется продуктивностью разработчиков.
Чтобы сделать корректные выводы на основании величины бэклога, целесообразно сразу пойти немного дальше и выполнить анализ задач в бэклоге:
Если существенная доля запросов на изменения не имеет оценки трудозатрат, полезно провести анализ практики / скорости оценки запросов в бэклоге.
Доля времени разработчиков на эксплуатацию
Чем менее качественный код, тем больше разработчикам приходится отвлекаться на эксплуатацию и в частности поддержку. Мы уже ввели выше показатель Incident Rate, который помимо прочего показывает, насколько много ресурсов компания направляет на “тушение пожаров”. Этот показатель уточняет, как много разработчиков в составе “пожарных бригад”.
Почему важен
Маркер качества разработки и способности разработки решать новые запросы, не занимаясь текущими вопросами эксплуатации.
Как измерять
Для расчета метрики нужно выделить трудозатраты разработчиков за некоторый период времени на развитие (анализ и реализацию новых запросов на изменения) и поделить на общий бюджет рабочего времени разработчиков за тот же период времени.
Расчет можно выполнить на основании данных учетных систем разработки (Jira, RedMine, …). При отсутствии объективных данных можно опираться на экспертную оценку руководителей отделов / групп разработчиков.
Как использовать
Значения выше 15-20% говорят о серьезном отвлечении разработчиков от вопросов развития. В совокупности с большим бэклогом это говорит о наличии проблемы с качеством реализации изменений.
Дальнейшие действия могут включать в себя:

Мы рассмотрели еще три показателя, которые касаются разработки. Наконец, перейдем к заключительному показателю, который покажет насколько результативны усилия ИТ-департамена с точки зрения потребителей.
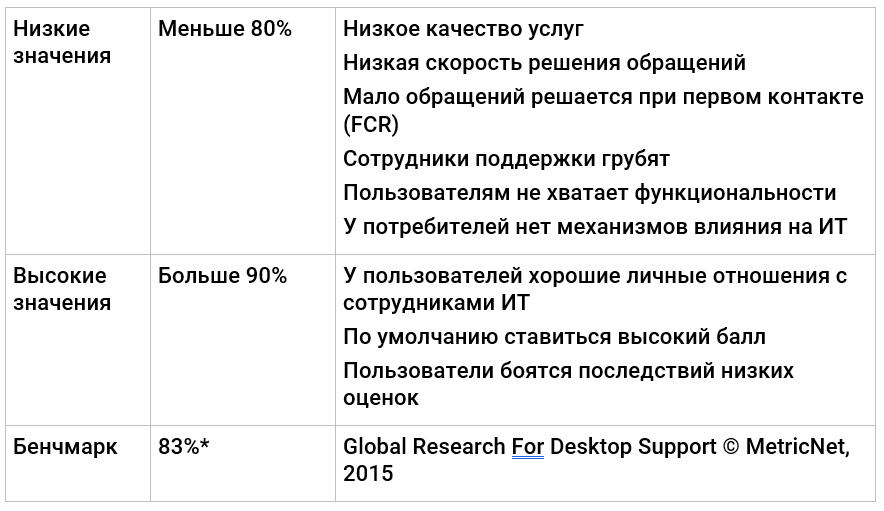
Удовлетворенность потребителей услуг
Заключительный показатель в списке, который показывает итоговое восприятие работы ИТ-подразделения – насколько ИТ соответствуют тем ожиданиям, которые есть у потребителей ИТ-услуг организации.
Почему важен
Показывает ИТ глазами потребителей услуг.
Как измерять
Есть множество способов померить удовлетворенность потребителей. Они в основном не специфичны для ИТ:
Так или иначе, оценку удовлетворенности можно получить из целевого опроса или путем извлечение информации из текущей оперативной деятельности – в зависимости от отношений бизнеса и ИТ и доступных данных уместно использовать один или другой или оба способа.
Как использовать
Средний показатель по компании вряд ли расскажет что-то интересно, поэтому нужно сразу установить наименее удовлетворенные группы пользователей и на что жалуются. Если для сбора данных используется опросник, уместно туда включить утверждения и предложить указать степень согласия, например:
Проанализировать связь между низкими оценками конкретных групп потребителей и:
Мы рассмотрели восемь основных показателей, которые помогут получить первое впечатление от ИТ-департамента. Напомним, что на их основе некорректно делать выводы об качестве работы ИТ или эффективности менеджмента – они лишь расставляют акценты и намечают дорогу для дальнейшего анализа. Это дорогу мы постарались наметить.
Все показатели можно сгруппировать следующим образом. Естественный, но не обязательный порядок анализа:
Восемь – не какая-то волшебная цифра, каждую группу показателей можно дополнить для получения более детальной и точной картины (например, блок “Результаты ИТ” можно дополнить метрикой, связанной с успешностью проектов, а в “Эксплуатацию и поддержку” также включить метрики производительности и непрерывности). И напротив, если для расчета показателя данные недоступны, метрику соответствующей области можно заменить интервью или экспертной оценкой. Помните, что измерения и метрики – не единственный инструмент управленца, хотя, как правило, выводы, сделанные на основе цифр заслуживают большего доверия.
