В этом году в Альманах itSMF вошел целый ряд переводных статей, опубликованных ранее на портале Real ITSM. Но две статьи, написанные нашими авторами и опубликованные в Альманахе, мы представляем читателям портала впервые — это «Истоки DevOps» Олега Скрынника и «От измерений к действиям. Системная динамика в управлении ИТ» Павла Дёмина.
От измерений к действиям. Системная динамика в управлении ИТ
Мы научились измерять ИТ-процессы и используем метрики для принятия управленческих решений. Но как часто планы действий приводят к желаемому результату? Как часто мы боремся за высокие значения конкретных показателей, упуская общую картинку? В рамках данной статьи автор ставит задачу продемонстрировать, как инструменты системной динамики могут быть использованы для повышения качества измерений, оценки и совершенствования ИТ-процессов. Текст не претендует на всесторонний анализ системы управления ИТ, равно как и разработку сколько-нибудь полной ее модели, а, скорее, является обзором базовых положений системной динамики на примере актуальных проблем ИТ-менеджмента.
Управление сложностью
ITIL® определяет сервис-менеджмент как совокупность организационных способностей для предоставления ценности заказчикам в форме услуг[1]. Но едва ли одного наличия способностей достаточно для эффективного предоставления услуг высокого качества. Способности должны быть организованы в систему – систему управления ИТ-услугами, которая согласно ISO/IEC 20000, включает в себя «взаимосвязанные и взаимодействующие элементы, среди которых политики, цели, планы, процессы, документация и ресурсы для проектирования, преобразования, предоставления и совершенствования услуг»[2]. Сложность (количество элементов и логика их взаимодействия) – неотъемлемая характеристика систем управления, и системы управления ИТ-услугами – не исключение.
Рост сложности приводит ко все большей неопределенности состояния системы. Для сокращения этой неопределенности менеджеры прибегают к метрикам. Метрики помогают количественно оценить текущую ситуацию и поддерживают принятие управленческих решений. В то же время их использование сопряжено с рядом принципиальных сложностей.
Первая из них – фрагментарность картины объекта управления, которую эти показатели рисуют. Как правило, разработка метрик не вызывает больших трудностей, но подтверждение их полноты и корректности – серьезный вопрос. В книге «ITSM. Руководство по измерению»[3] предложен структурный подход, который опирается на наличие по каждому процессу назначения и проработанного списка ключевых практик. Опыт показывает, что с формулировкой назначения сложности возникают редко, а вот составление списка ключевых практик, несмотря на обилие источников для вдохновения (CSF в ITIL, Key practices в COBIT5 Enabling Processes и так далее) – в значительной степени творческое упражнение, качество результатов которого во многом определяется опытом исполнителя.
Вторая сложность связана с учетом взаимного влияния и трактовки показателей в масштабе системы. Даже если на регулярной основе рассчитывается множество правильных показателей, даже если эти показатели сложены в сбалансированную систему KPI, даже если результаты оценок попадают в красивые дашборды, а отчеты оказываются на столах у правильных людей, оценка достижений в охвате процесса, системы управления, организации в целом, анализ и разработка эффективных планов действий на их основе остаются нетривиальным задачами. Дж. Стерман в книге Business Dynamics: Systems Thinking and Modeling for a Complex World утверждает, что структура системы определяет ее поведение в динамике. Это значит, что добавление или изменение состояния ее элементов вызывает сложное нелинейное поведение системы. Чем сложнее система и больше связей, тем менее интуитивным будет ее поведение. Способности человека понять, как сложная система, состояние которой определяется целым набором показателей, которые: а) характеризуют разные уровни системы; б) могут конфликтовать между собой; в) разнонаправленно и неравномерно меняются с течением времени – серьезно ограничены.
Недостаток понимания общей картины приводит к тому, что Дж. Форрестер в книге «Мировая динамика» описывает как четыре «характерные ошибки, свойственные решению большинства социальных проблем». Несмотря на то, что Форрестер рассматривает мировую систему, проблемы будут удивительно близки каждому ИТ-менеджеру.
| # | Дж.Форрестер «Мировая динамика» | Пример из управления ИТ |
| Ошибка 1 | Реагирование на часть симптомов проблемы создает новую форму поведения системы, что ведет к новым проблемам. | Ограничение маршрутизаций инцидентов с целью сокращения «футбола» приводит к искусственному удержанию объектов (например, на первой линии) и появлению параллельных каналов коммуникации (с сотрудниками, которые действительно могут решить инцидент). Это приводит к потерям времени, снижению уровня документирования решений и искажению показателя FLR. |
| Ошибка 2 | Стремление добиться кратковременного улучшения приводит к трудностям в долговременном плане. | Выполнение экстренных изменений для завершения одного проекта повышает риски будущих отказов из-за слабого «следа» таких изменений и привнесенных в инфраструктуру проблем. |
| Ошибка 3 | Цели подсистем противоречат общим целям системы. | Отдел сопровождения преследует цель снизить риски при внесении изменений в продуктивную среду, что тормозит развитие. |
| Ошибка 4 | Менеджеры предпринимают попытки воздействовать на систему в тех ее частях, где она малочувствительна к такому воздействию и где усилия и деньги тратятся с малым эффектом. | Высокие затраты на сопровождение приводят к сокращению бюджета на сопровождение, однако цель экономии так и не достигается из-за роста потерь от простоев и оплаты переработок.
|
К счастью, система управления ИТ-услугами – далеко не первая известная человечеству система управления, а ИТ-менеджеры далеко не одиноки в своих поисках инструментов анализа сложных систем в динамике. С 1960-ых, благодаря Форрестеру и его последователям, мир знает системную динамику –направление в изучении сложных систем, исследующее их поведение во времени и в зависимости от структуры элементов системы и взаимодействия между ними.
Ситуация
Одно из ключевых правил в системной динамике – моделировать не систему, а проблему[4]. Это позволяет точнее задать границы модели, исключить из рассмотрения несущественные факторы и переменные, сфокусироваться на поиске способов достижения конкретных результатов. В противном случае, исследователь рискует «вскипятить океан», так и не добыв и ложки соли[5].
Пожалуй, самое яркое описание сложившейся сегодня во многих ИТ-организаций кризисных ситуаций можно найти в книге The DevOps Handbook[6]. Авторы назвали явление «хроническим конфликтом» (The Core Chronic Conflict) и описали, как «нисходящую спираль, обусловленную конфликтом интересов между разработкой и эксплуатация, которая приводит к замедлению времени вывода решений в продуктив, снижению качества услуг, увеличению количества и продолжительности сбоев, накапливанию проблем и перманентному тушению пожаров». Из текста можно выделить две ключевые проблемы:
- Рост времени вывода решений в продуктив (Lead Time[7])
- Снижение доступности услуг (Service Uptime)
Известно, что быстрое развитие и надежная эксплуатация – цели конфликтующие. Чем быстрее мы хотим проводить изменения, тем на большие риски мы идем с точки зрения качества услуг. Чем большую защиту продуктивной среды мы хотим обеспечить, тем больше времени у нас уйдет на реализацию изменений. Тупик? В настоящий момент Lean, Agile, автоматизация ИТ-процессов и виртуализация инфраструктуры меняют наше представление о том, как может быть разрешен этот конфликт.
Динамическая гипотеза
Помимо определения проблемы, для построения модели является важным выдвинуть динамическую гипотезу, которая формулируется посредством размышления о том, как связаны ключевые переменные и чем регулируется их состояние[8] – ее наличие позволяет продуманно приступить непосредственно к моделированию.
Наша динамическая гипотеза будет состоять в том, что ИТ сталкивается со все возрастающим спросом со стороны бизнеса, который не может быть удовлетворен в условиях ограниченных ресурсов. В то же время увеличенная частота и низкий уровень планирования и контроля изменений в силу постоянного давления со стороны бизнеса приводит к привнесению в инфраструктуру большого количества дефектов (проблем), которые затем приводят к отказам и забирают существенную долю ресурсов на их устранение (рис.1).
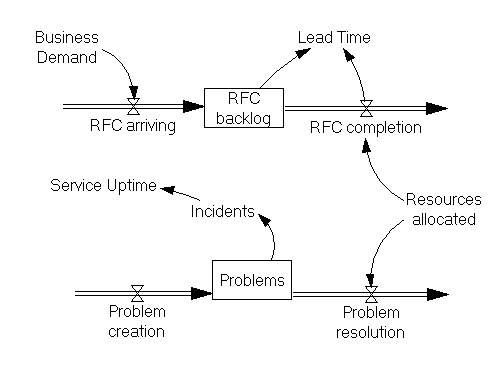
В терминах системной динамики входящие запросы на изменения и привносимые в инфраструктуру проблемы аккумулируются в накопителях – RFC backlog и Problems (изображаются прямоугольником). Слева и справа к накопителям подходят потоки: входящий поток обеспечивает наполнение накопителя, исходящий – отток. Состояние накопителя может быть изменено только входящими и исходящими потоками, но не другими переменными. Это ограничение имеет большое значение с точки зрения управления: например, мы не можем изменить количество открытых проблем напрямую, мы лишь можем повлиять на потоки – скорость их выявления и/или решения.
Переменные, которые не являются накопителями и потоками, называются динамическими (или вспомогательными). В отличие от взаимодействия потоков и накопителей, которое в системной динамике называется физическим (или материальным), связи, включающие динамические переменные, отражают информационное взаимодействие – переменные передают информацию о своем значении для расчета значений связанных переменных.
Например, скорость выполнения изменений (RFC completion) и решения проблем (Problem resolution) определяется тем, как много ресурсов доступно для этих работ (Resources allocated). В свою очередь, скорость выполнения изменений (RFC completion) и величина очереди (RFC backlog) определяет скорость вывода решений в продуктив (Lead Time). Количество проблем определяет количество инцидентов, а количество инцидентов за период – доступность услуг (Service Uptime).
Однако не все связи на представленных в статье диаграммах имеют очевидный способ задания значения переменной как функции от связанных переменных (например, количество инцидентов от количества проблем). Местами для расчетов требуется определение дополнительных переменных (например, для расчета доступности на основании количества инцидентов нужно также знать их продолжительность, пересечения нарушений по времени и так далее). По части переменных не очевидна ни размерность, ни способ измерения (Business Demand).
Это намеренное упрощение, которое, во-первых, позволит уместить статью на разумном количестве страниц, во-вторых, крайне важно для быстрого анализа проблем на качественном уровне и как можно более быстрого получения наглядной картины их возникновения и развития. Далее диаграммы могут быть детализированы в отдельных аспектах, чтобы быть пригодными для имитационного моделирования.
Рост времени вывода решений в продуктив
С точки зрения динамики системы очень важно, что Lead Time на самом деле складывается из времени ожидания изменения в очереди и времени работы над изменением: Lead Time = Queue Time + Processing Time (рис.2). В свою очередь время ожидания каждого нового RFC в очереди зависит от того, сколько RFC уже содержится в бэклоге и как много RFC выполняется на заданном отрезке времени: Queue Time = RFC Backlog/RFC completion. Например, если RFC backlog = 100 RFCs и RFCs completion = 50 RFCs/месяц, Queue Time будет равен 2 месяцам (здесь и далее речь идет о средней величине).
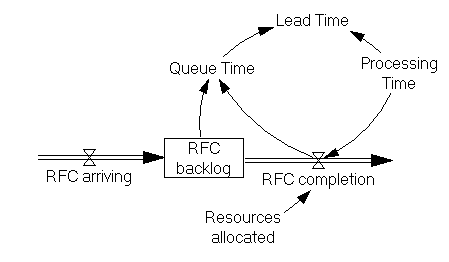
Важно, что значение RFC backlog меняется каждый период времени за счет входящих и исходящих потоков. Таким образом, если RFC arriving = const = 60 и RFC completion = const = 50, то значение Backlog будет увеличиваться на 10 RFC каждый период времени, динамически влияя на связанные переменные – Queue Time, и далее по цепочке на Lead Time.
Очевидно, что значение Lead Time напрямую зависит от состояния накопителя RFC backlog, и работа по снижению Lead Time почти неизбежно потребует мер по воздействию на потоки RFC arriving и RFC completion с целью снижения уровня в накопителе. Однако увеличивающийся бэклог влияет на Lead Time не только через рост Queue Time, в действительности запускается целая серия не столь очевидных каскадных эффектов, которые затрагивают в том числе и Processing Time (рис.3).
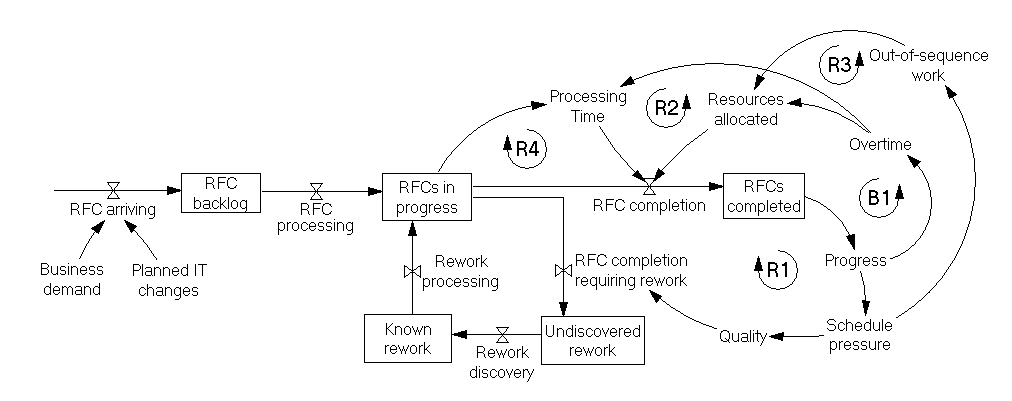
Если по тем или иным причинам изменения выполняются несвоевременно, это приводит к росту давления на сотрудников, что повышает количество ошибок. Как следствие, часть уже выполненных работ требует доработок, что увеличивает количество RFC в работе (R1). В системной динамике контур R1 называется петлей обратной связи – в данном случае усиливающей (reinforcing loop, обозначаются буквой R). Если переменная состоит в усиливающей петле обратной связи, то ее изменение (рост или падение) приведет к дальнейшему изменению в том же направлении.
В системной динамике также используется еще один тип петли обратной связи – балансирующая (balancing loop, обозначаются буквой B). Если переменная состоит в балансирующей петле обратной связи, то ее изменение (рост или падение) приведет к ее дальнейшему изменению в противоположном направлении. Отставание от расписания, как правило, приводит к тому, что сотрудники остаются на рабочем месте внеурочно, что увеличивает ресурсы, доступные для выполнения работ (B1), однако побочным эффектом является выгорание, усталость и снижение продуктивности сотрудников, что увеличивает время выполнения задач (R2).
Бизнес-руководство, чьи планы могут быть связаны со своевременным завершением ИТ-проектов и проведением изменений, в условиях отставания от графика усиливает давление на ИТ и вынуждает запускать в работу все большее количество срочных изменений, которые влезают вперед очереди, отвлекая ресурсы от плановых работ (R3).
Это запускает еще один любопытный эффект. Пересохший канал RFC completion и постоянное отвлечение внеочередной срочной работой, приводит к тому, что число активных задач находится на высоком уровне. Сотрудники тратят время на переключение, как следствие, падает продуктивность и время, требуемое для выполнения работы (R4). Увеличивается хаос в планировании, затрудняется контроль и координация выполнения задач.
Помимо прочего, низкий уровень планирования и координации изменений, посредственное документирование вследствие нехватки времени, большое количество экстренных изменений, проведение незарегистрированных изменений, укрупнение релизов для внедрения целой пачки стоящих в очереди изменений в одно сервисное окно, приводят к повышенным рискам и, как следствие, сбоям. Разберем, как система себя ведет в динамике, решая задачи сопровождения и поддержки.
Низкая доступность услуг
К недоступности приводят инциденты, которые в свою очередь являются следствием проблем – дефектов, которые накапливаются в ИТ-инфраструктуре. Что является источником проблем? Мы уже знаем, что неудачно проведенные изменения привносят в инфраструктуру проблемы, которые могут привести к инциденту сразу, а более коварные проявятся позднее (или, если повезет, не проявятся вовсе). Однако можно ли объяснить низкую доступность услуг только возросшим потоком изменений? Едва ли. Важными факторами также являются общая «хрупкость» ИТ-инфраструктуры, которая определяется количеством элементов и их качеством (надежностью), временем эксплуатации оборудования и его естественным износом, архитектурой и отказоустойчивостью.
Управление инцидентами – работа с симптоматикой, устранение же корневых причин инцидентов (проблем) требует плановой работы в рамках управления проблемами[9]. Мало где эта задача выполняется на «отлично», что приводит к накапливанию проблем, росту количества инцидентов и падению доступности услуг.
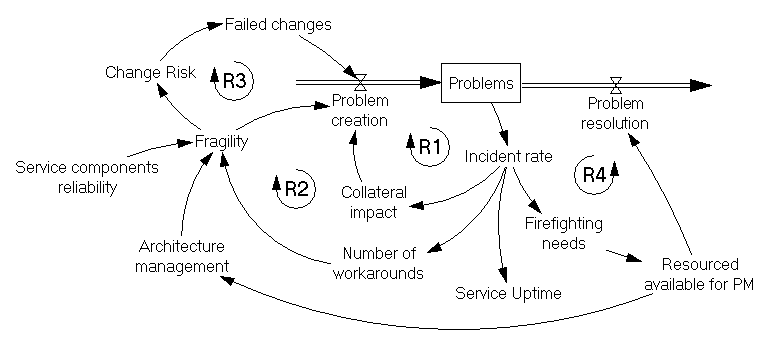
Итак, накопившиеся проблемы вызывают инциденты. Чем больше проблем накопилось, тем чаще будут происходить инциденты. Инциденты сами по себе могут запускать цепную реакцию в инфраструктуре, приводя к появлению новых проблем со связанными элементами инфраструктуры. Также к появлению новых проблем могут приводить действия сотрудников – решение инцидентов требует скорости, а значит сопряжено с ошибками (R1).
Кроме того, для скорейшего восстановления услуг нередко применяются так называемые обходные решения, которые позволяют в кратчайшие сроки возобновить работу пользователей, но «консервируют» проблему, повышая комплексность, а значит и хрупкость инфраструктуры (R2). Системы с большей «охотой» падают даже от незначительных изменений, в том числе в силу плохого планирования изменений – никто уже давно толком не знает, как это работает[10] (R3).
Устранение большого количества инцидентов требует большого количества ресурсов, которые, конечно, ограничены. Чем больше времени сотрудники проводят за «тушением пожаров», тем меньше остается на плановую работу. Исходящий поток Problem Resolution пересыхает (R4). Проблемы продолжают накапливаться, приводя к новым возгораниям, требуя еще больших усилий по их тушению. ИТ-подразделение стремительно оказывается на выжженной земле в ловушке перманентного огня, вынужденное бросать все силы на спасение услуг. Примечательно, что многие сотрудники могут быть совершенно не против такого положения дел: быть героями приятно и почетно, кроме того, за переработки доплачивают по двойной ставке.
Казалось бы, куда уж хуже? Однако рассмотрим ситуацию в более широком контексте, и увидим, что такое положение дел может запросто привести к росту затрат на сопровождение (переработки, расход комплектующих, оплата работы подрядчиков, дополнительное резервирование и так далее), но результат так и не будет обеспечен – низкая доступность продолжит приводить к потерям бизнеса.
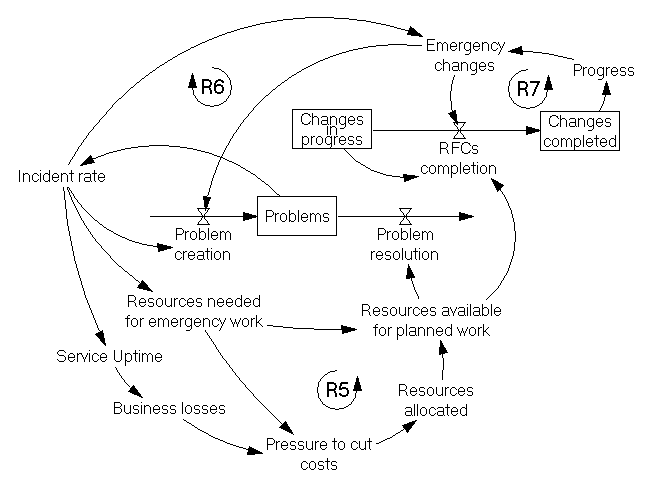
В результате как ИТ-руководство, которое должно обеспечить исполнение бюджета, так и бизнес-руководство, неудовлетворенное работой ИТ, усиливают давление по сокращению затрат (рис.5). В этих условиях еще меньше ресурсов становятся доступны для плановой работы (R5). Количество проблем растет, продолжая вызывать все большее количество срочной работы и отнимая все большее количество ресурсов на ее выполнение.
В то же время, растет не только количество, но также масштаб и продолжительность сбоев – отступать становиться некуда, для выхода из кризисных ситуаций все чаще требуется проведение срочных изменений, связанных с повышенными рисками (R6).
Ресурсы, занятые тушением пожаров, становятся все менее доступны не только для управления проблемами, но и для проведения изменений. Бизнес-руководство в условиях необходимости достижения хоть каких-то результатов также усиливает давление и запускает в работу все большее количество срочных изменений. Дальнейшее развитие событий нам уже известно (R7).
Со временем реактивная работа становится нормой. Принятые правила взаимодействия между командами, коммуникации с подрядчиками, планирование расписания изменений и другие практики постепенно отражают мир, в котором ИТ хрупки и нестабильны. Сотрудников, которые начинают заниматься плановой работой, быстро выдергивают и бросают на тушение пожаров. ИТ-специалисты со временем занимают пассивное положение: «все равно ничего не изменить». Все знают о том, что можно работать внеурочно, и рассчитывать на дополнительный доход. Вновь выходящие сотрудники быстро впитывают заведенный порядок и становятся частью «пожарных бригад», для которых хрупкая ИТ-инфраструктура, низкий уровень доступности, отсутствие времени на плановую работы и вечно недовольный бизнес – это нормальное положение вещей[11].
Ловушки для ИТ-организации
Видно, что на тернистом пути ИТ-организации по удовлетворению потребностей бизнеса лежит целая серия капканов, о которых мало кто не знает, но все равно попадается. При этом рассмотренные эффекты в разделе «Рост времени вывода решений в продуктив» не являются специфичными для ИТ-менеджмента и присущи любой проектной работе / цепочке создания ценности, а петли из раздела «Низкая доступность услуг» справедливы для всех работ по сопровождению и поддержке.
| Ключевые ловушки, связанные с цепочкой создания ценности | Ключевые ловушки, связанные с сопровождением |
| · Замедление в выполнении работы приводит к еще большему замедлению.
· Количество ошибок склонно только возрастать, отнимая ресурсы на повторное выполнение работ. · Отставание от расписания увеличивает количество срочной работы, отнимая ресурсы от плановой работы и увеличивая количество задач, одновременно находящихся в работе. · Это, в свою очередь, осложняет координацию трудовых ресурсы и снижает продуктивность сотрудников, способствуя еще больше отставанию от расписания. |
· Накапливающиеся проблемы приводят к инцидентам, а те – к новым проблемам.
· Для сокращения времени недоступности применяются обходные решения, которые увеличивают комплексность инфраструктуры, делая ее менее устойчивой. · Управление инцидентами отнимает существенную долю ресурсов, не оставляя сотрудникам времени на плановую работу. · Потери от простоев и дополнительные расходы на сопровождение усиливают давление по сокращению затрат, еще больше сокращая ресурсы на плановую работу и увеличивая технический долг.
|
В какой степени та или иная петля проявит себя, зависит от множества факторов: зрелости ИТ-менеджмента, культуры сотрудников, истории (как система вела себя в прошлом), отношений с бизнесом, уровня доверия и так далее. Однако рискну сказать, что, несмотря на возможные существенные различия в степени корреляции между переменными, представленные причинно-следственные зависимости описывают общую природу вещей.
Это означает, что даже однократные изменения ключевых переменных с последующей стабильной динамикой на новом уровне вызывают сложное нелинейное изменение в поведении системы[12]. Как мы имели возможность убедиться, рост количества инцидентов может запускать целую серию каскадных эффектов, которые приведут ИТ-организацию к состоянию перманентного тушения пожаров. При этом даже если первоначальная причина, запустившая цепочку событий, прекратит свою существование, системе потребуются колоссальные усилия, чтобы вернуться в состояние равновесия.
От проблемы к решению
Но есть и хорошие новости. Усиливающие петли обратной связи таят огромную опасность, но также являются мощным инструментом в руках менеджера. Напомню, что в таких контурах начальное изменение переменной стимулирует ее дальнейшее изменение в первоначальном направлении. Таким образом, если удастся добиться изменения переменной в нужном нам направлении, можно запустить процесс «оздоровления» во всем контуре, а так как переменные входят сразу в несколько контуров – запустить ту же серию каскадных эффектов, которая теперь будет работать на нас. Как же это сделать?
Одна из ключевых идей ITIL – для эффективной работы ИТ-организации требуется развивать ее способности (capabilities). Развивать способности можно посредством реализации ключевых практик. Стандартизировать изменения для экономии времени на планирование и сокращения рисков внедрения. Минимизировать количество экстренных изменений, чтобы не отвлекать сотрудников внеплановой работой, обеспечить учет и, опять же, снизить риски. Иметь классификатор для быстрой и точной передачи инцидентов на ответственную группу. Обеспечить повторное использование знаний, например, для передачи части решений на первую линию. В общем случае развитие способностей позволяет:
- Выполнять работу быстрее.
- Выполнять работу с меньшим количеством ошибок.
- Выполнять работу дешевле[13].
В конечном счете, развитые способности должны повысить пропускную способность (throughput) процесса. Развитие же способностей, в свою очередь, обеспечивается накоплением и повторным использованием знаний. Упрощенно механизм иллюстрирует следующая диаграмма.
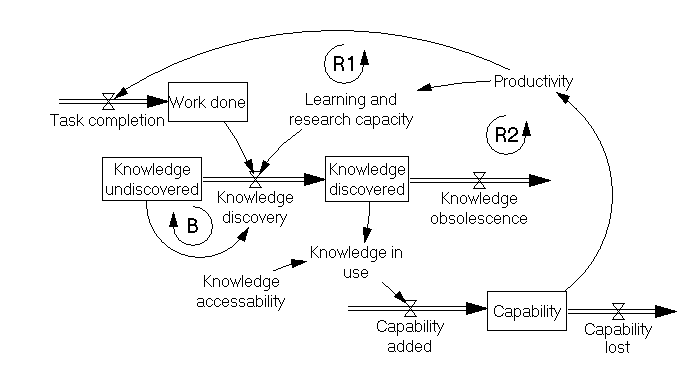
Поэтому совершенно не удивительно, что в таких процессах, как управление инцидентами и управление изменениями, можно обнаружить встроенные механизмы выявления и накопления знаний (Major Incident Review, Post-Implementation Review). В то время как процессы управления инцидентами и управления изменениями работают на повышение своей пропускной способности, элемент выявления знаний в управлении проблемами выполняет другую задачу – наполнение своего бэклога.

Так как для исполнения своего назначения – устранения корневых причин инцидентов – управление проблемами должно одинаково хорошо справляться и с выявлением проблем (Problem Discovery) и с их устранением (Problem Resolution), в книге «ITSM. Руководство по измерению» в качестве метрики результативности и предложен коэффициент продуктивности процесса[14].
Как может быть повышена пропускная способность цепочки создания ценности нам в красках описывает DevOps Handbook, а диаграммы дают возможность удобного поиска точек приложения усилий с быстрым получением представления о возможных последствиях. На рис.8 собраны вместе разобранные выше паттерны поведения системы с ключевыми потоками, накопителями и петлями обратной связи.
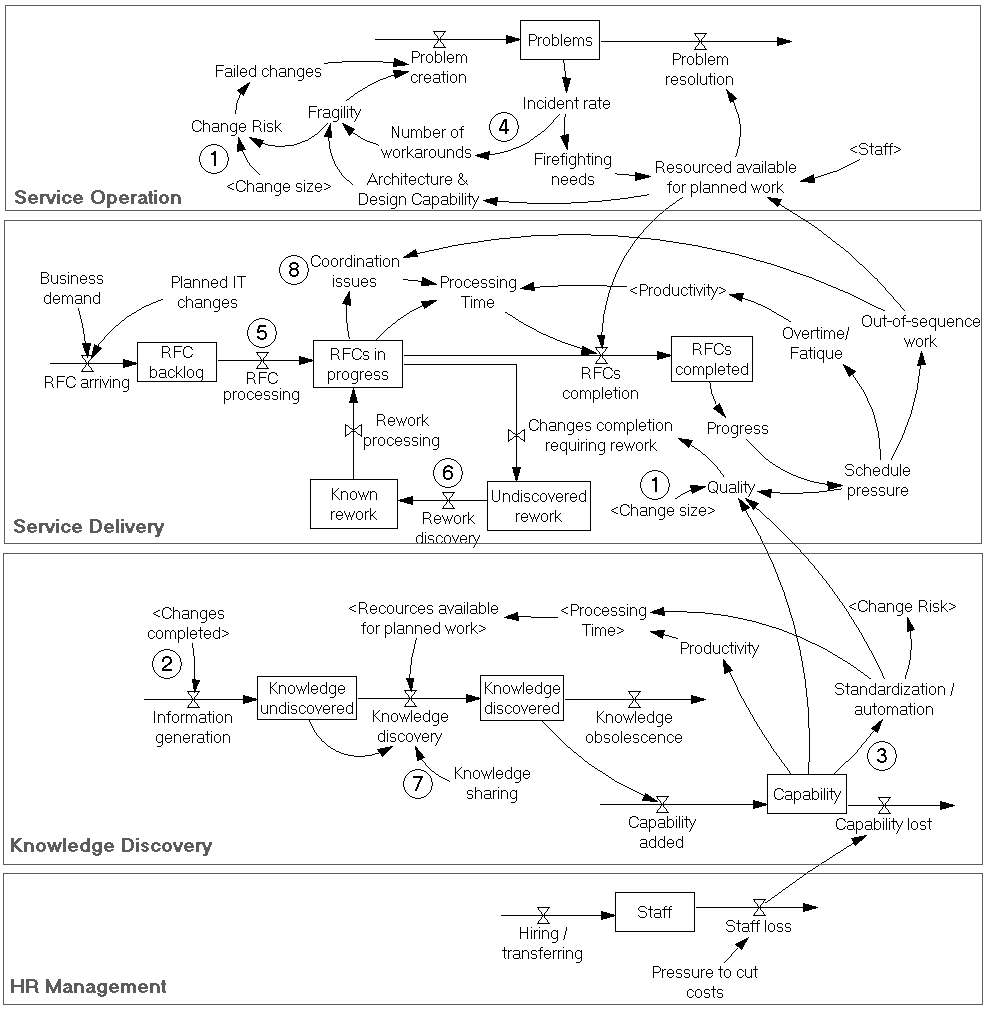
| # | Практики DevOps |
| 1 | Один из ключевых посылов DevOps – уменьшать размер задач. Это с одной стороны снизит риски неудачных внедрений (крупные релизы сложнее планировать и проводить из-за большого количества связей), с другой – снизит количество возвратов на доработку. |
| 2 | Уменьшение размера задач, улучшает ритм выполнения задач и позволяет быстрее нарабатывать опыт. |
| 3 | Накопленные знания повышают способности по выполнению работ и позволяют часть из них стандартизировать и автоматизировать. |
| 4 | Ограничение применения обходных решений позволяет не допускать рост сложности инфраструктуры и технического долга. |
| 5 | Ограничение числа задач в работе уменьшает число прерываний специалистов и потери времени на переключение, уменьшает хаос в планировании и координации выполнения работ. |
| 6 | Ранняя обратная связь сокращает время выявления дефектов. |
| 7 | Практика разбора ошибок без обвинений и осуждений (blameless review) повышает способность команд к усвоению уроков даже из горького опыта. |
| 8 | Визуализация задач повышает качество планирования и координации выполнения работ. |
Следующие шаги
После того, как проблема проанализирована, и получено понимание, какие действия необходимы, начинается самое интересное – пора действовать. Но, как правило, это сопряжено с колоссальной сложностью и инерцией системы. Чтобы что-то изменить, менеджеру нужно:
- Пойти на риск и запастись терпением. Например, выход из ловушки с тушением пожаров, связан с постепенным перераспределением и, возможно, привлечением дополнительных ресурсов на проактивную работу. Не первых порах это может даже увеличить затраты и снизить время доступности (устранение проблем потребует сервисных окон). В этот момент инициатива может быть признана неудачной и все вернется на круги своя.
- Убедить пойти на риск и запастись терпением руководство и коллег. И для решения этой задачи, конечно, приведенных в статье картинок явно недостаточно – нужны модели, которые покажут количественные изменения конкретных показателей на заданном горизонте.
На следующем шаге системная динамика предлагает переходить от качественных диаграмм к математическим моделям. Модели строятся на основе потоковых диаграмм (stocks and flows diagrams, именно они представлены в данной статье), но требуют задания функций зависимости одних переменных от других. Получившаяся имитационная модель позволяет безболезненно исследовать разные сценарии поведения систем в зависимости от изменения произвольного числа переменных, проводить анализ чувствительности и разрабатывать эффективные и убедительные планы действий.
Представленные в статье диаграммы являются паттернами (в системной динамике их часто называют системными архетипами – схемами или шаблонами поведения типовых проблем управления[15]), свойственными всем системам управления ИТ-услугами, которые могут быть использованы для сборок таких моделей.
Однако даже из анализа диаграмм на качественном уровне можно извлечь немало пользы. Они наглядно показывают механизм появления и развития проблемы, и позволяют структурно анализировать причины неудовлетворительных результатов. Не сомневаюсь, что такие картинки уже могут находиться в голове многих профессиональных ИТ-менеджеров и вряд ли станут для них открытием. Однако диаграммы задают каркас мыслительного процесса, который удерживает от попадания в ловушки ошибочных допущений и помогает разобраться с внутренними противоречиями, которые являются неотъемлемым атрибутом всех сложных систем. А главное – дает возможность оставаться на том уровне, где видны значимые явления в масштабе всей системы.
Вот лишь некоторые примеры сценариев использования, которые нам удалось опробовать в практике Cleverics:
| Задача | Использование инструментов системной динамики (причинно-следственные и потоковые диаграммы, системные архетипы) |
| Измерение[16]
|
· Идентификации и верификация метрик на основе причинно-следственных диаграмм, построенных по процессам.
· Определение не только отложенных, но и опережающих показателей для любых целевых KPI ITSM-инициатив и операционной деятельности ИТ. |
| Оценка
|
· Использование причинно-следственных и потоковых диаграмм в качестве ментальной карты для диагностики ИТ-процессов: структурирование наблюдений за счет привязки к элементам упрощает переход к оценке и выводам.
· Связи между зависимыми переменным и связанными с ними метриками показывают возможные способы агрегирования показателей и выделения значимых для объекта управления областей оценки. |
| Планирование совершенствования
|
· Разработка рекомендаций по результатам диагностики. Часто управленческие решения принимаются на основании отдельных метрик и призваны точечно влиять на их значения, в то время как требуется скоординированное воздействие на целый ряд переменных с учетом циклов[17]. Диаграммы позволяют планировать воздействие на переменные с учетом контуров, в которые они входят, за счет комплексного понимания причинно-следственных связей. |
| Обучение и семинары с заказчиком | · Причинно-следственные диаграммы являются наглядной иллюстрацией для слушателей курсов механизмов появления и развития проблем, а также инструментов для их решения, которые предлагает ITIL, DevOps и так далее.
· Причинно-следственные и потоковые диаграммы позволяют более конструктивно обсуждать проблемы и решения в рамках работы группы экспертов, имеющих разное мнение об истинном положении вещей. |
Есть в полученных результатах и личная радость автора этих строк. С тех пор как я открыл первые книги про менеджмент, везде читаю о системном подходе. И если на уровне идеи все довольно очевидно, то, что значит «анализ совокупного влияния» и «системное мышление» на практике, для меня долгое время оставалось загадкой. Возможно, теперь станет чуть яснее: инструменты системной динамики дают синтаксис, с помощью которого идея системного подхода обретает вполне различимые очертания. И это, конечно, очень вдохновляет.
[1] ITIL® Service Strategy,2.1.2
[2] ISO/IEC 20000
[3] Исайченко Д., Журавлев Р., «ITSM. Руководство по измерению»
[4] Sterman J. Business Dynamics: Systems Thinking and Modeling for a Complex World, с.79
[5] Ethan M. Rasiel, The McKinsey Way
[6] Gene Kim, Patrick Debois, John Willis, Jez Humble, John Allspaw. The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations.
[7] Здесь и далее в скобках указан англоязычный вариант переменной, который из соображений компактности используется на диаграммах.
[8] Каталевский Д., Основы имитационного моделирования и системного анализа в управлении, с.203
[9] Известны варианты организации сервис-менеджмента, при которых устранение корневых причин инцидентов, выполняется в рамках процесса управления инцидентами. Это никак не влияет на объяснение «физики» описываемых явлений.
[10] DevOps в динамике: https://realitsm.ru/2017/03/dynamics_of_devops_p1/
[11] Sterman J. Business Dynamics: Systems Thinking and Modeling for a Complex World, p.72
[12] Каталевский Д., Основы имитационного моделирования и системного анализа в управлении, с.211
[13] Kim Warren. Strategy Dynamics Essentials, с.156
[14] Коэффициент продуктивности процесса управления проблемами Problem Performance Index определяется следующей формулой: , где C – количество проблем, закрытых за период, O – количество проблем, открытых по окончании периода, N – количество новых проблем, зарегистрированных за период и не закрытых к моменту его окончания.
[15] Понятие впервые введено и П.Сенге в книге «Пятая дисциплина: искусство и практика самообучающейся организации».
[16] DevOps в динамике — 2. Метрики: https://realitsm.ru/2017/05/dynamics_of_devops_p2/
[17] From Key Success Factors to Key Success Loops: https://thesystemsthinker.com/from-key-success-factors-to-key-success-loops/


Павел, браво! Статья вышла увлекательной, научной и очень практичной.