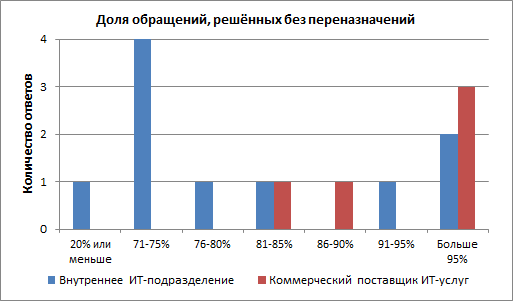
Решение без переназначений (результаты)
В июне нами был проведён опрос «Решение без переназначений». Вопрос был поставлен следующим образом: какая доля обращений за технической поддержкой, поступающих от пользователей, решается без переназначений? Пришло время обсудить результаты. За время проведения опроса поступило 15 ответов. Маловато для статистически значимого результата (может быть, было бы правильно предусмотреть ещё один вариант ответа «Неизвестно»?). Но будем опираться на эту выборку. Тем более что результаты, на мой взгляд, вполне ожидаемы: в среднем коммерческие поставщики услуг продемонстрировали более высокий результат. Это, вероятно, вызвано двумя основными факторами. Во-первых, у коммерческих поставщиков на одного заказчика, как правило, приходится меньшее число групп. И во-вторых, коммерческие поставщики в…